The Ink & Switch Dispatch
Keep up-to-date with the lab's latest findings, appearances, and happenings by subscribing to our newsletter. For a sneak peek, browse the archive.
2024 Sep 5
Today’s cloud services have very mature access control features. These systems depend on a key architectural detail: they are able to rely on encapsulation by taking advantage of the network boundary. Since data is not available to read or write directly by the client, a privileged guard process is able to apply arbitrary access control rules. This process retrieves and/or mutates data on behalf of clients.
This power unfortunately comes at a price: since auth is on the hot path of every request — and generally depends on a central single-source-of-truth auth database — authorization at scale often bottlenecks overall application performance. And yet, an attacker that is able to bypass the auth part of the request lifecycle has unmitigated access to arbitrarily read, change, or delete the application’s data. This is to say nothing of the complexity of building, deploying, and maintaining cloud architectures to get that network boundary in the first place!
For local-first software to be successful in many production contexts, it needs to provide similar features without relying on a central authorization server. The local-first setting does not have the luxury of a network boundary: access control must travel with the data itself and work without a central guard.
There are also some tricky edge cases due to causal consistency. What should happen to honest operations that causally depend on content that’s later discovered to be malicious? What is the best strategy to handle operations from an agent that was revoked concurrently, especially given that “back-dating” operations is always possible. If a document has exactly two admins (and many non-admin users), what should happen if the admins concurrently revoke each other (for instance, one is malicious)?
To address the above challenges, we’ve started work on Beehive: a project focused on local-first access control. Our goal is to design and build a production ready instance of such a system which is general enough for most local-first applications.
To date, the local-first ecosystem has primarily used a purely pull-based model where users manually decide which changes to accept. This approach is often sufficient for personal projects: each user can manually decide which peers to connect to and which changes should be applied. On the other hand, many production contexts have lower trust, require higher alignment, and are ideally low touch enough so that it’s not up to each person in a large organization to separately and manually infer who to trust. As a rough north star, we’re keeping the following use cases in mind:
Cryptography has a reputation for being slow, especially if there’s crypto-heavy code running on low-powered devices. To have a performance margin that can cover a large range of practical use cases, Beehive aims to run efficiently over at least ten-of-thousands of documents, millions of readers, thousands of writers, and hundreds of admins/superusers.
Since authorization, authentication, and identity are often conflated, it is worth highlighting that Beehive deliberately excludes user identity (i.e. the binding of a human identity to an application’s identifier like a public key). In our initial community consultations we found that there are many different identity mechanisms that developers downstream of Beehive would like to use. As such, we’re designing the system to be decentralized and secure, and leave name registration/discovery and user verification (e.g. email or social) to a future layer above Beehive.
The following are left out of our design goals:
Most client/server backends place data at the bottom, and compute over it. In that model, auth is just another kind of computation. Leaving access control to a central process is not possible in a local-first context. In our context, the auth layer must act as a foundation.
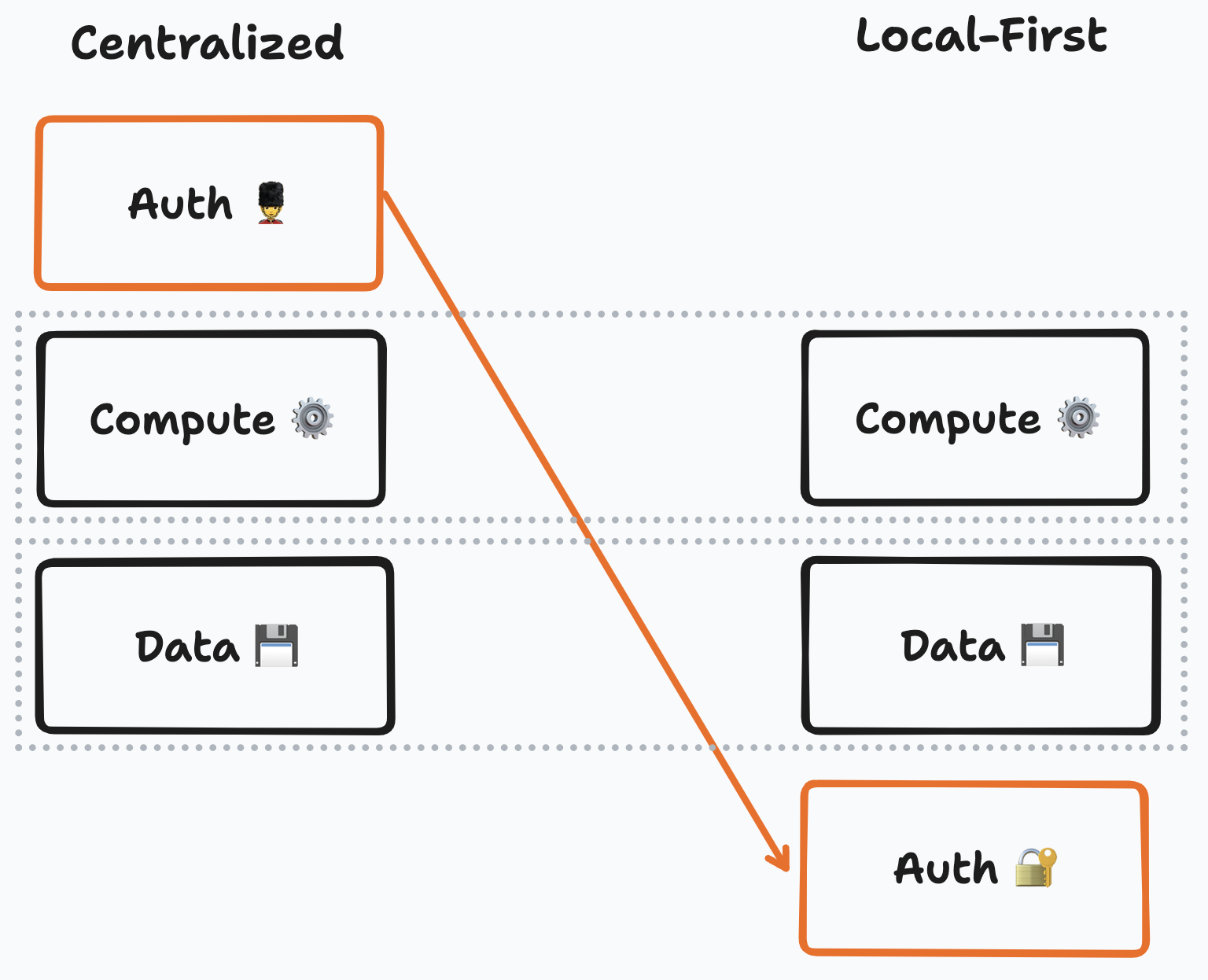
Static authorization typically impacts the design of all other layers of a project. As an intuition, the storage layer will need to support data that is encrypted-at-rest, and so its design has a dependency on the auth layer. This means that since the design of an authorization mechanism may impose downstream constraints, its design should consider such potential impacts on the design of the rest of the stack. As much as possible, this project attempts to minimize imposing such constraints on other layers.
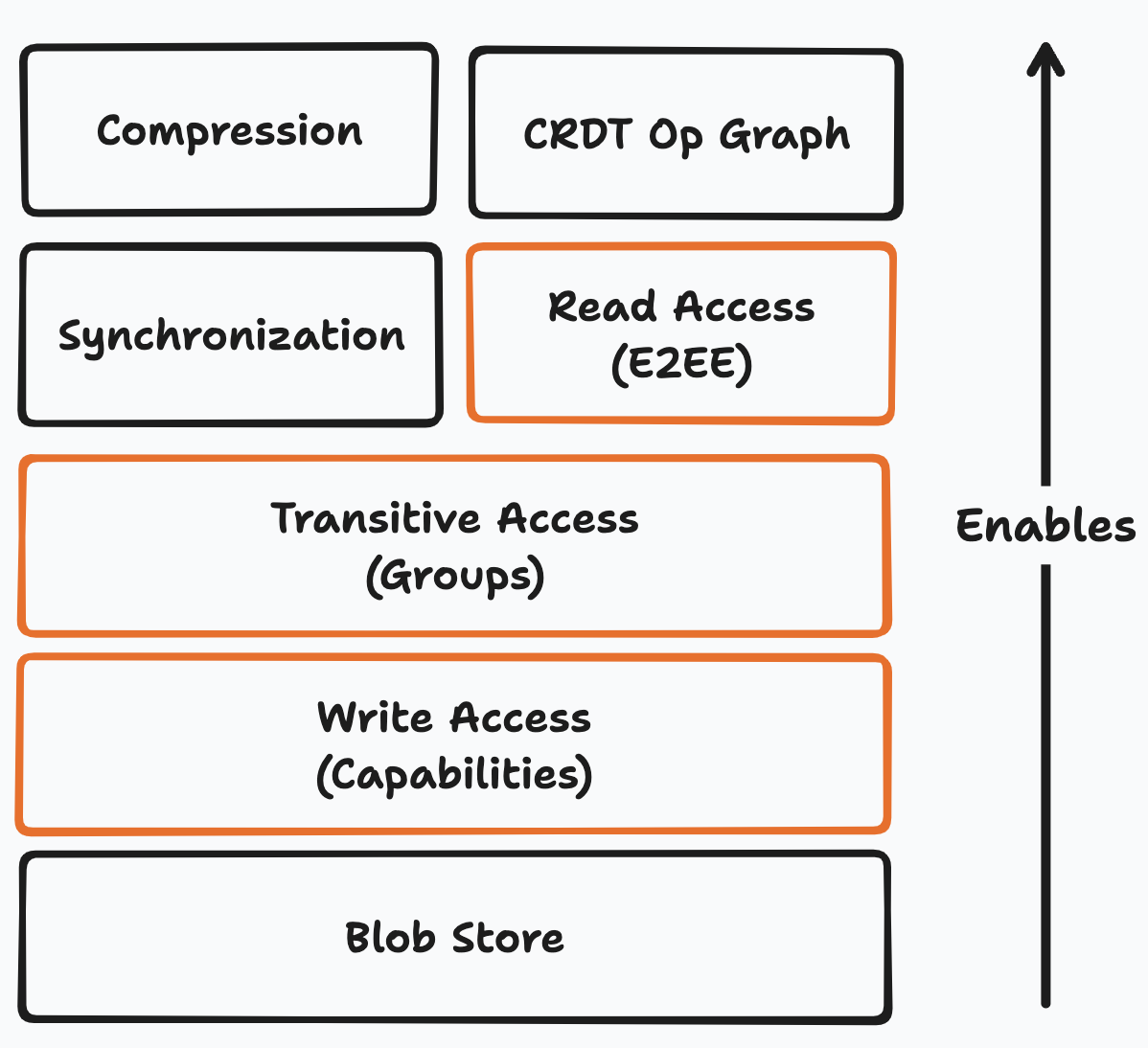
Beehive (as currently designed) carves out three layers to handle this:
These three have a strong dependency between each other. Capabilities enable use to manage groups, and groups let us share keys for E2EE. We will go into more detail on all three in future posts, but in the meantime here is a very high level treatment:
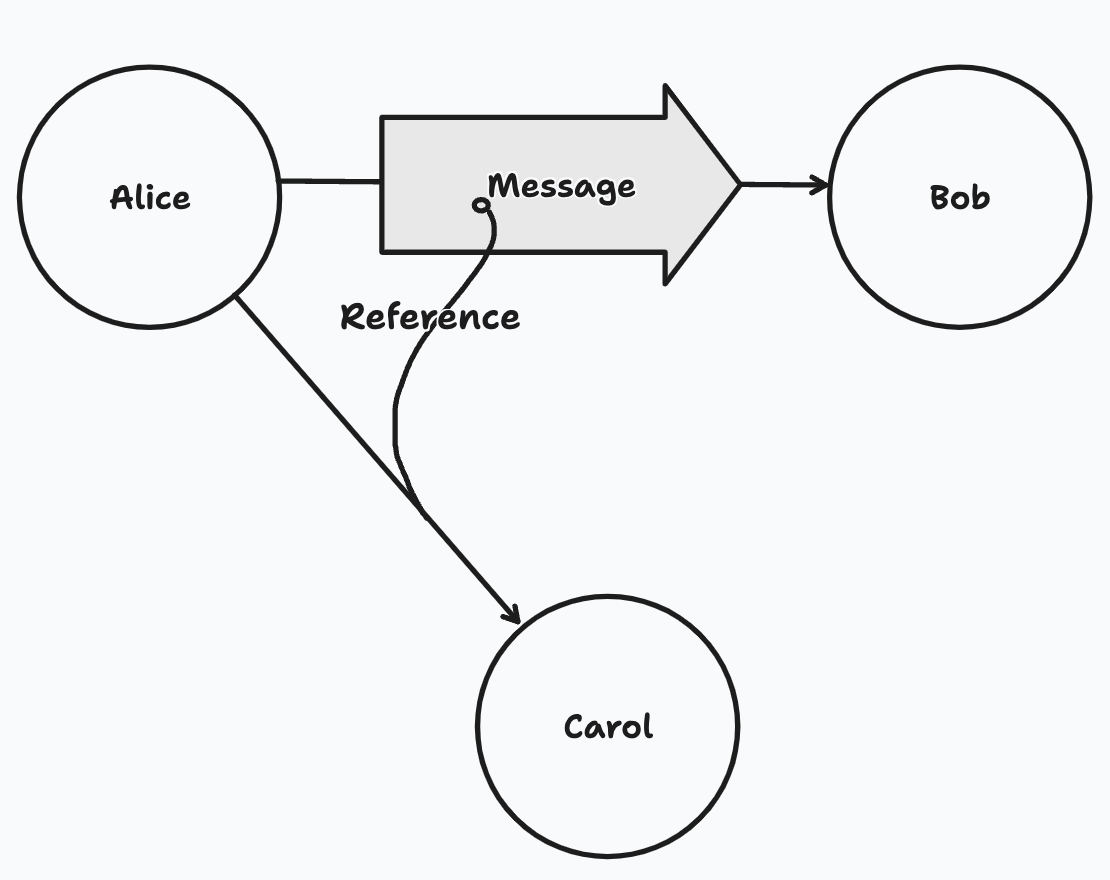
A diagram showing Alice delegating to Bob her existing access to Carol
Capabilities and delegation form the basic access control mechanism that are known to be very expressive. In short: all Automerge documents get identified by a public key, and delegate control over themselves to other public keys. This provides stateless self-certification with a cryptographic proof. Public keys in the system can represent anything: other documents, users, groups, or anything else. This is a very low-level mechanism that can be used to model high level concepts like powerboxes, roles, device groups, and more with very little code, all while remaining extensible to new patterns.
Object-capabilities (AKA “ocap”) are “fail-stop”, meaning that they intentionally stop working if there’s a network partition to preserve consistency over availability. Since local-first operates under partition (e.g. offline), parts of the classic object-capability design are not suitable. Certificate capabilities such as SPKI/SDSI, zcap-ld and UCAN are partition-tolerant, but depend on stateless certificate chains which is highly scalable but somewhat limits their flexibility. We propose a system between the two: convergent capabilities (“concap” for short) which contain CRDT state to get the benefits of both while retaining suitability for local-first applications.
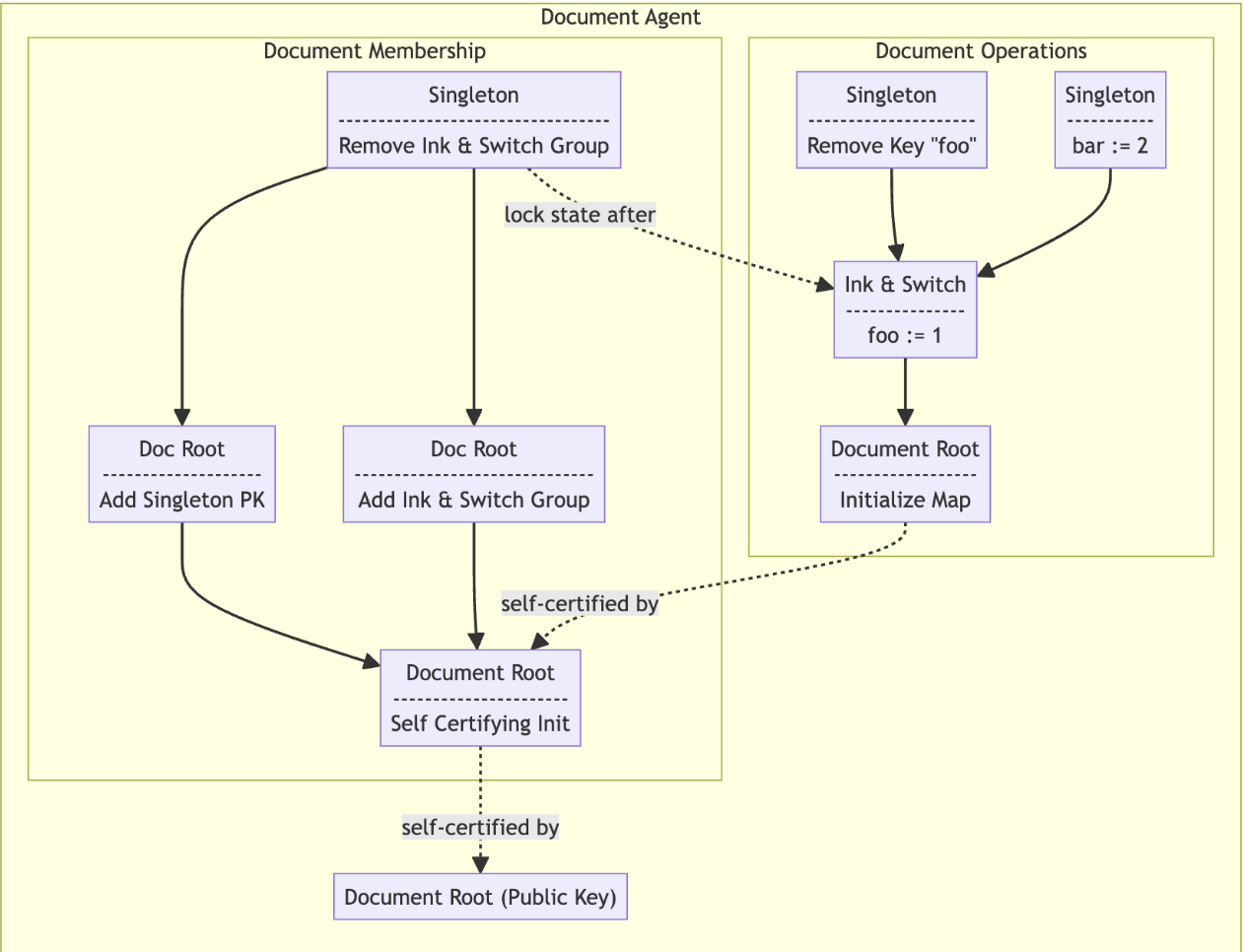
A Beehive document in isolation, with a simplified view of its stateful delegation graph.
Concurrent access control will always have some tricky situations. The big obvious ones are what to do if two admins concurrently revoke each other, or happened if operations depend on others that were revoked, and how to handle maliciously back-dated updates. There is quite a lot to discuss on this topic, so we’ll leave it for a future post.
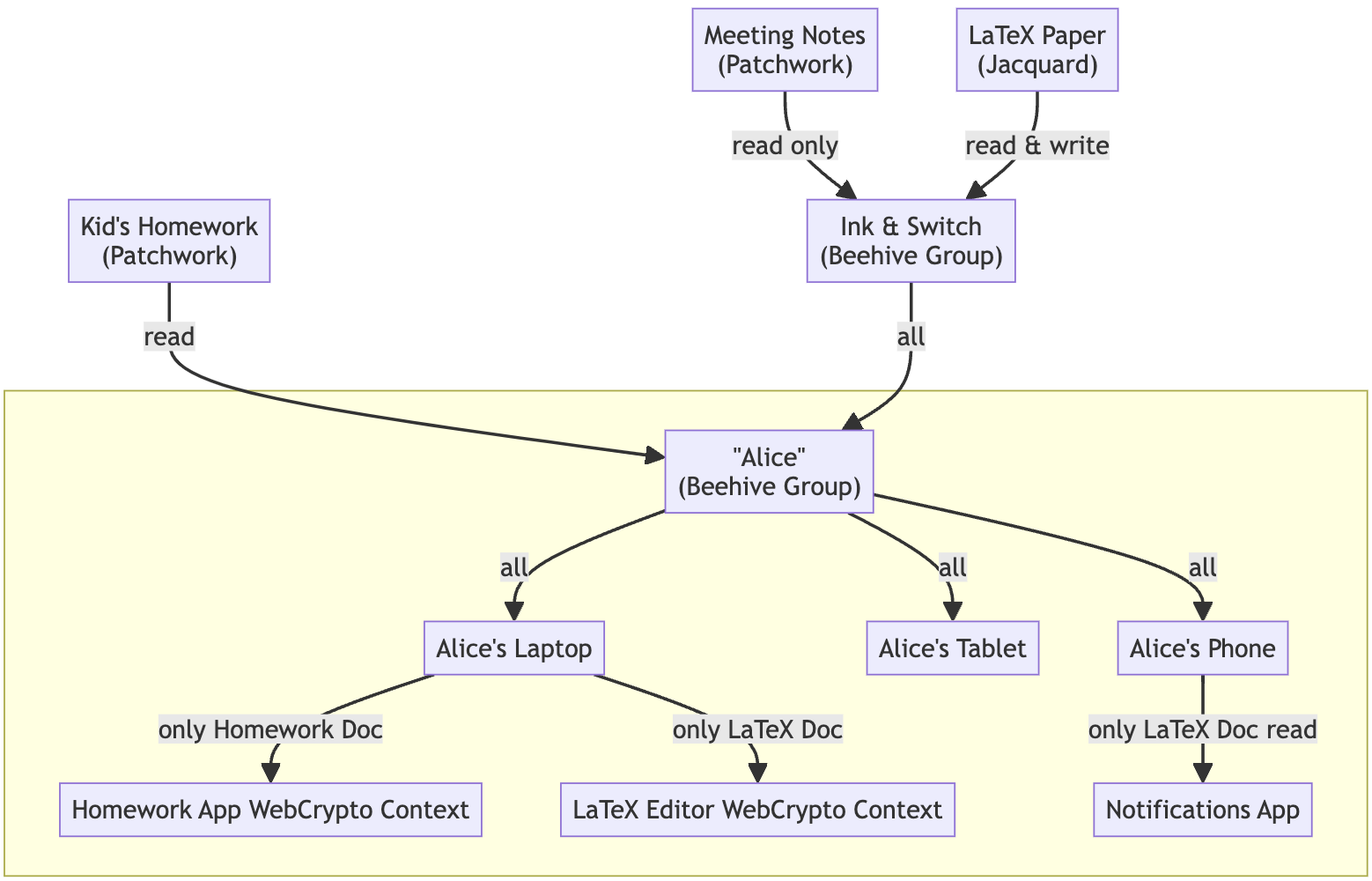
A Beehive group showing how devices can be managed behind a proxy (‘Alice’). Documents in this scenario only need to know about Alice, not every device.
Groups are built on top of convergent capabilities. They’re “just” a thin design pattern, but help model things like user devices, teams, and more. By following the delegations between groups, we can discover which public keys have what kind of access to a certain document. This provides a handy abstraction over teams and user devices. By following the links, it both lets a writer know who has read access (i.e. who to share keys for the latest E2EE chunk with), and lets the trust-minimized sync engine know which documents the current device can request from the server.
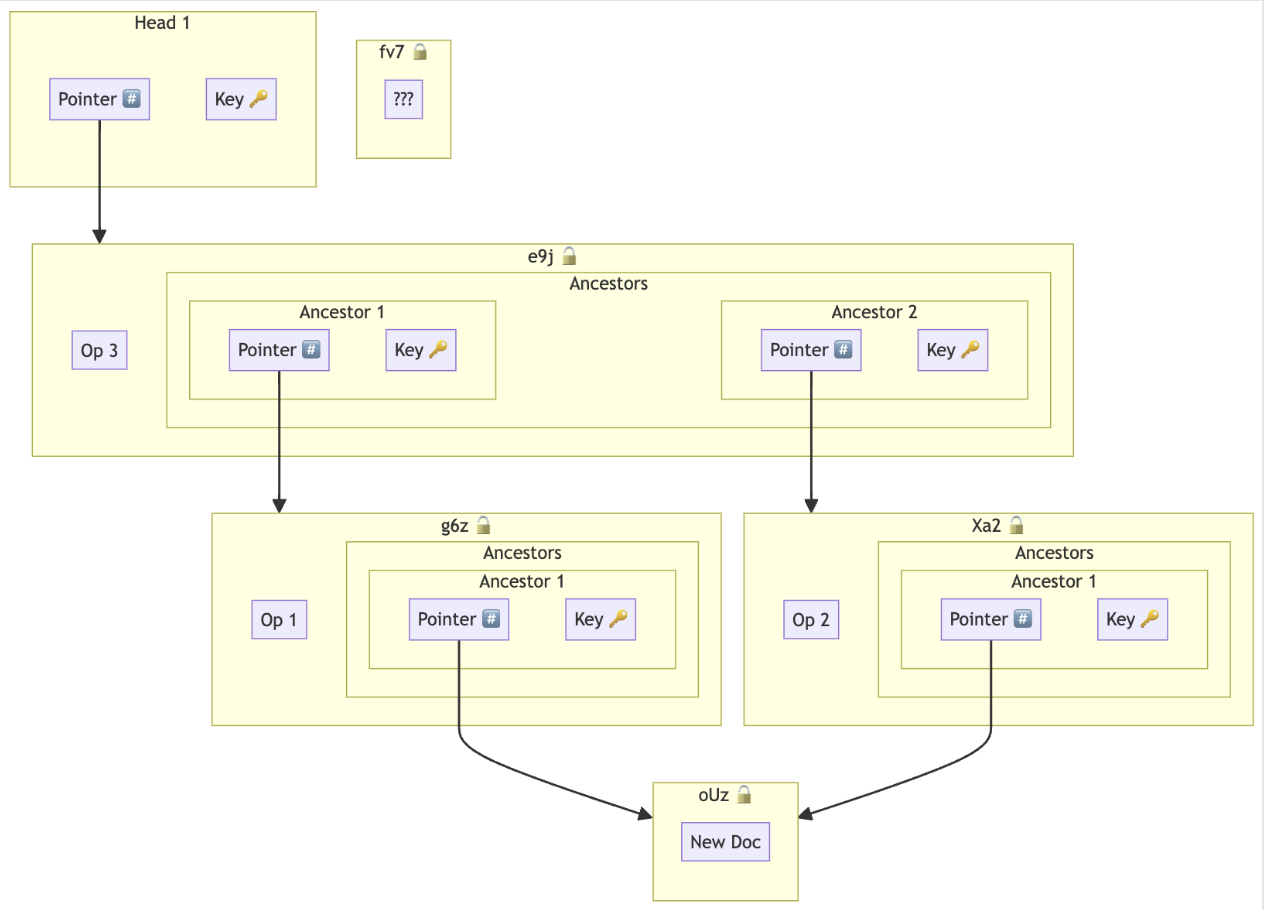
Causal key management: a strategy for managing E2EE keys based on the causal structure of a document. Similar to a Cryptree, having the key to some encrypted chunk lets you iteratively discover the rest of the keys for that chunk’s causal history, but not its parents or siblings.
Data in Beehive is encrypted-at-rest. Encrypting every Automerge operation separately would lead to very large documents that cannot be compressed. Instead we use the Automerge Binary Format to compress-then-encrypt ranges of changes. We expect these encryption boundaries to change over time as parts of the document become more stable, so we need a way to manage (and prune) a potentially large number of keys with changing envelope boundaries.
We achieve the above by including the keys to all of their causal predessesor chunks. This sacrifices forward secrecy (FS) — leaking old message keys in the case of a later compromised key — but retains secrecy of concurrent and future chunks. Of course “leaking” anything sounds bad. However, unlike ephemeral messaging (e.g. Signal) where not all users are nessesarily expected to have the entire chat history, CRDTs like Automerge require access to the entire causal history in order to render a view. This means that in all scenarios we need to pass around all historical keys, whether or not they’re in the same encryption envelope. We believe that this choice is appropriate for static control context on documents that require the entire history. As a nice side-effect of this choice, we also gain flexibility and simplicity.
In this design, keys behave a bit like pointers, so we can apply all of the standard data structure pointer indirection tricks to do smooth updates to encryption boundaries. This is fairly well-developed at this stage, so we will save a deeper exploration of this topic for a future post.
E2EE raises a new issue: there is no such thing as perfect security. All encryption algorithms are deemed secure with respect to some explicitly-defined assumptions (such as the difficulty of factoring large primes or group operations). There may be mathematical breakthroughs, edge cases discovered, or new hardware that render your choice of encryption algorithm useless. Even more worse, keys can be accidentally leaked or devices stolen. While we can revoke future write access, if someone has the data and the symmetric key, then they have the ability to read that data. The best practice is to have defense in depth: don’t make ciphertexts retrievable by anyone, but only those with “pull access” or higher. “Pull” is weaker than the more familiar “read” and “write” access effects: it’s only the ability to retrieve bytes from the network but not decrypt or modify them. This is especially helpful for trust-minimizing sync servers, since by definition they cannot have the ability to see the plaintext if we want to claim E2EE.
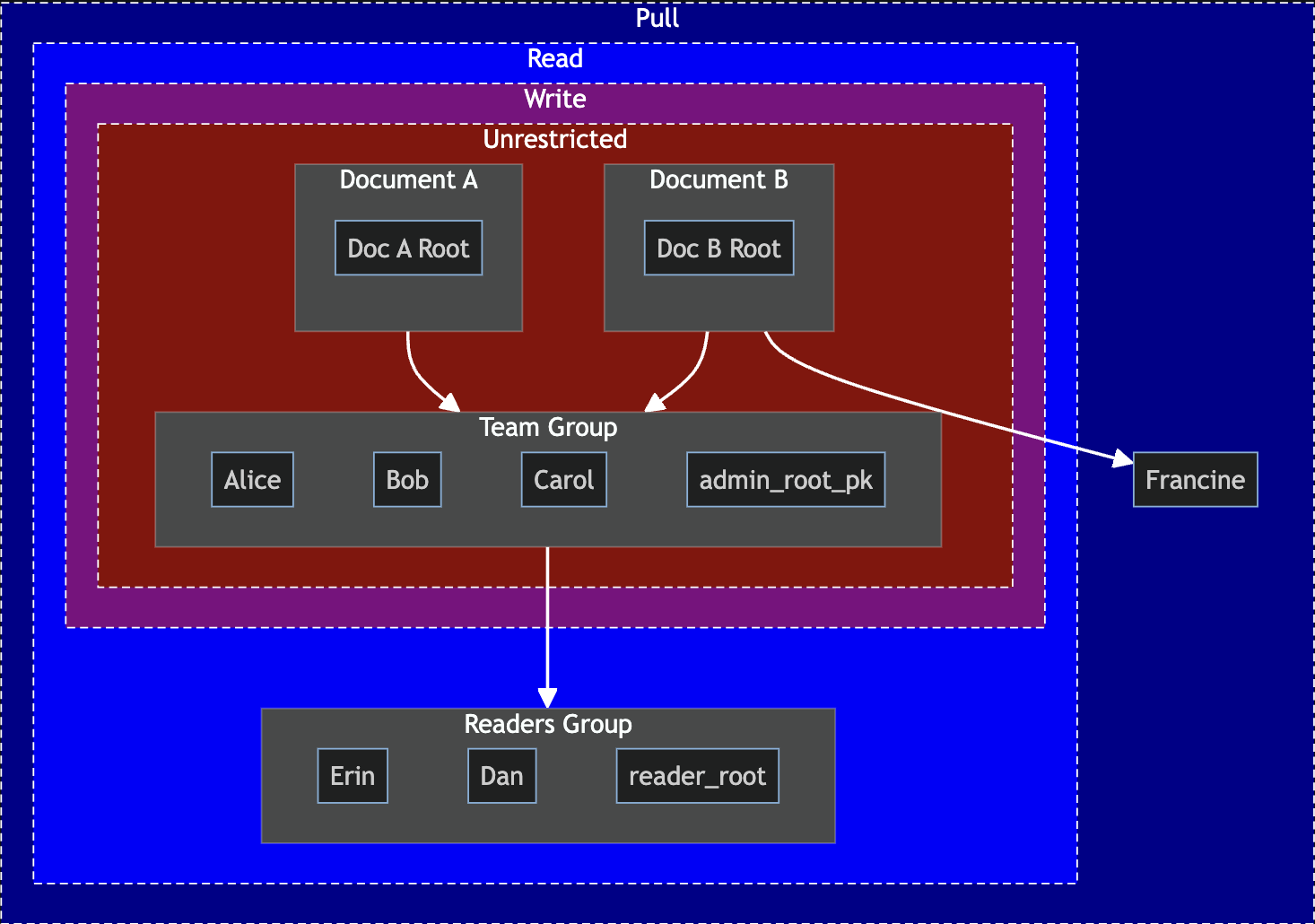
An example of delegation across the Beehive access effect types
If we want to move towards an ecosystem of interchangeable relays, minimizing trust on such relays is a must. Our approach (perhaps unsurprisingly) is to end-to-end encrypt the data, removing read access from sync servers altogether. Under this regime, sync engines are “merely” a way to move random-looking bytes between clients.
There is another ongoing project at the lab focused improving data synchronization for peer-to-peer and via sync servers. We’ve realized that sync and secrecy strongly interact. Broadly speaking, sync protocols benefit from more metadata (to efficiently calculate deltas), but cryptographic protocols aim to minimize or eliminate metadata exposure. This tension extends across related systems, including merging E2EE compressed chunks, and determining if a peer has already received specific operations when a sync server cannot access them in plaintext.
Fortunately, combining these systems can sometimes result in more than the sum of their parts. For instance, convergent capabilities help facilitate the calculation of which documents are of interest to particular agent, helping the sync system know which documents to send deltas of. For these reasons, we’re treating synchronization and authorization as part of a larger, unified project, even though each will yield distinct artifacts.
Cryptographic code is notoriously difficult to debug, so we decided to start with design and move to code when we had some fairly good theories on how the basics of this system should work. Now that we’re at that point, we’ve very recently begun to implement this design. We’ll report on our progress in future posts, as well as dive deeper into some of the topics we touched on in the overview here.