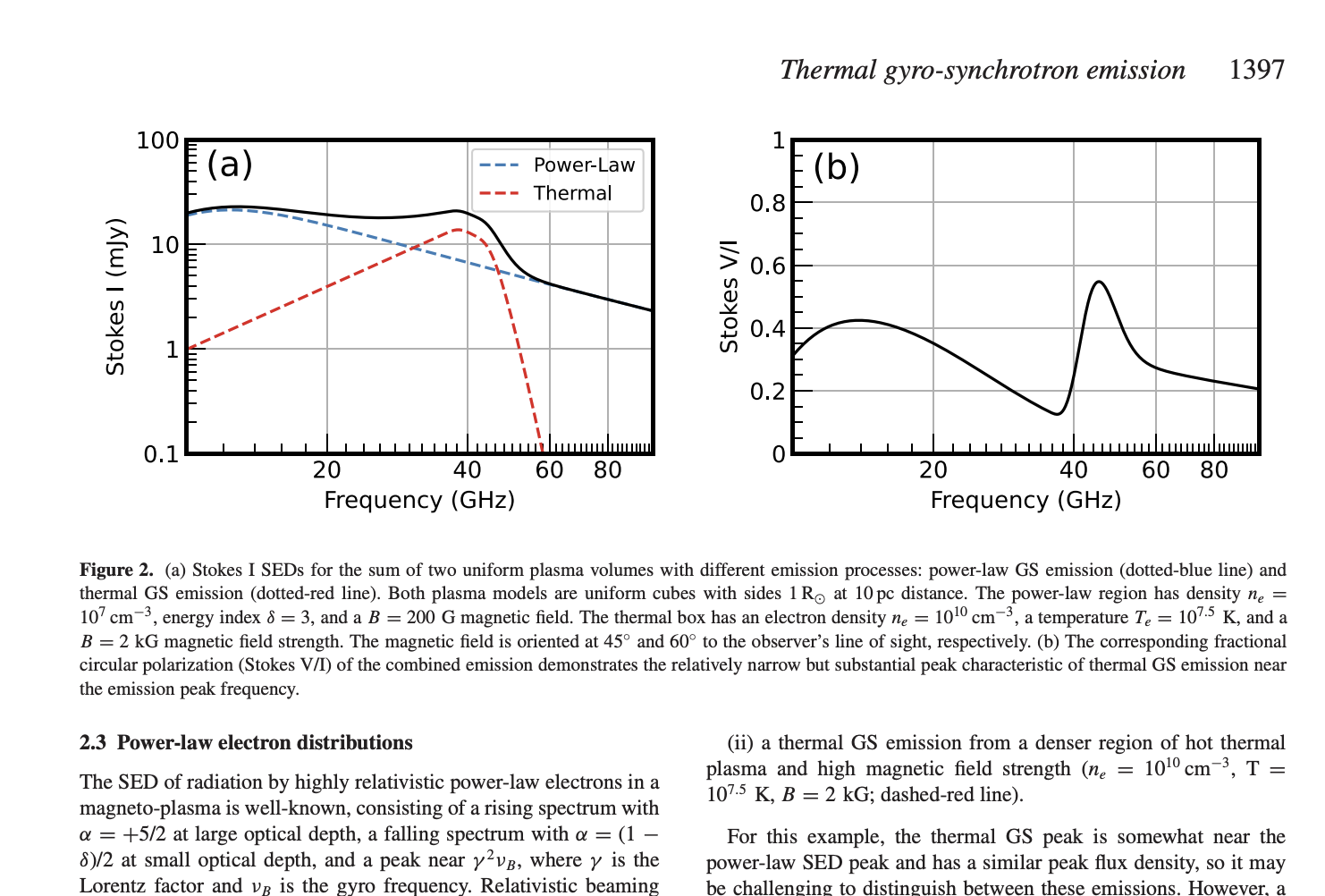
Consider a hypothetical astronomy paper. Measurements are collected from a telescope and written into a raw data file, which is reduced into a smaller CSV, which is loaded into a Python analysis notebook, which outputs further intermediate data files, as well as several visualizations as PNGs, which are then dragged into a web-based collaborative LaTeX editor where the team edits the paper and refines the charts.
This cobbling-together of tools and intermediate data files can cause serious problems for teams of researchers:
“How did we generate this chart?”: Researchers waste time remembering what script and data were used to generate a given chart or data table. And when an analysis gets updated, it’s tricky to remember what other steps need to be manually rerun to correctly update downstream results.
“Where’d that file go?”: The text, the figures, and the code for the paper are spread across various web apps and devices. Any collaborator can edit the paper text on the web, but the moment they want to edit a chart, they have to email their collaborator who has the code on their laptop. Sometimes the team even loses track of a file entirely.
“What’s changed recently?” Authors risk missing important changes made by their collaborators. It’s generally challenging to suggest or review changes; many “track changes” views present too much detail and are difficult to parse.
Through conversations with researchers in fields ranging from astrophysics to oceanography, we’ve learned that these kinds of problems cause daily friction, stealing focus from important work and even causing mistakes. Some researchers use software engineering tools like Git and Makefiles to help with these problems, but those tools are an awkward fit for exploratory research programming, and aren’t easily accessible to scientists who are less familiar with the command line.
On this project, we’re prototyping Jacquard: a collaborative environment for writing empirical research papers. The goal is to free up researchers to focus more on their core work of science and communication, and less on tedious bookkeeping. (The name “Jacquard” comes from the automated loom that was an important step in the history of computing.)
Jacquard builds on years of work at Ink & Switch, including most recently Patchwork: a browser-based local-first collaboration environment with powerful version control utilities like branching and history views.
We’re starting out by extending Patchwork to support the kinds of data needed by empirical research papers, like LaTeX files and data visualization scripts. From there, we aim to add on powerful capabilities like tracking provenance of derived artifacts or making suggestions on a branch. Throughout this process, the prototype should remain a simple web-based collaboration interface that’s accessible to researchers who don’t have prior experience with version control or build systems.
A couple notes about our process:
First, while we’re aiming to invent new collaboration workflows, supporting real science work requires integrating with existing tools as well. So we’ll be taking a pragmatic approach that meets scientists where they are, building bridges to existing desktop workflows and programs.
Second, while this work is related to efforts in scientific reproducibility, that’s not our top priority. Reproducibility efforts often focus on packaging up results once they’re completed; we’re more interested in supporting and accelerating the messy process of getting to the results in the first place.
We’ll be posting updates as we go on this blog. If you’d like to follow along, feel free to sign up for the Ink & Switch email newsletter to receive periodic emails about our progress. And if you’re an empirical researcher (in any discipline) and would like to talk with us about your experiences with these problems, we’d love to chat—please reach out at geoffrey@inkandswitch.com.
Scientific papers straddle two worlds. They’re thoughtfully crafted prose documents, but they’re also computational documents containing data analyses and visualizations. Today, the prose and computational parts of a paper often live in different environments and tools, which causes friction for teams of scientists.
For instance, one scientist told us that he keeps chart-generation code in a git repo, but collaborates with coauthors in the web-based Overleaf tool. Every time a chart changes, he needs to manually drag files from his computer into the browser. Meanwhile, his collaborators have little visibility into the code and data that generate charts.
Other scientists have told us about difficulties staying oriented as they move between a paper and the data pipelines that feed into it. A paper’s LaTeX source refers to a chart PNG file… but wait, which data file and Python script were used to generate that PNG?
We wondered: what if one collaboration environment could host both the text of the paper and the data visualization code, making it seamless to edit them together? Here’s a prototype:
Using a provenance graph to navigate a project and automatically propagate updates
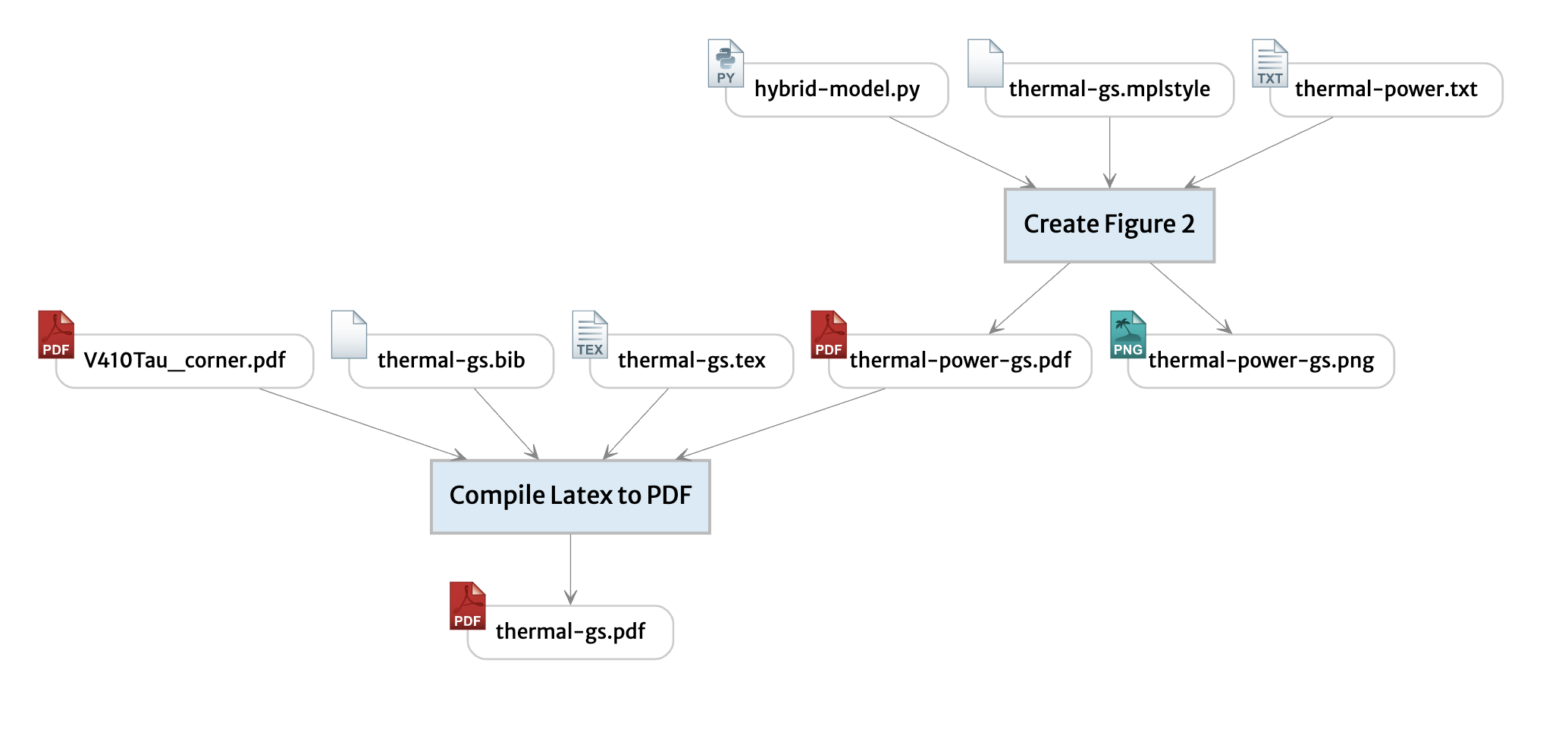
The demo shows a web-based collaboration environment with provenance — information about how computed artifacts were generated from source material. By keeping track of provenance, we know when an output file needs to be rebuilt, and we know how to do it. We can also use provenance to create a map of the project:
The build graph shows how files affect one another.
A core challenge we’re exploring in this prototype is how to integrate a collaborative web-based editor with the full power of running arbitrary computations on a Unix shell.
Behind the scenes of this demo, there is a watcher process which can be hosted on any computer, like a scientist’s own laptop or a cloud server. When the user requests a rebuild from the web interface, the watcher process detects the request, re-runs commands like the Python script or the LaTeX compiler, and syncs the results as well as provenance information back to the web view.
We think the ability to run the watcher process on any computer provides useful flexibility. At first, a scientist can easily try out computations without needing to initially make them portable or run them in a Docker container. At the same time, it’s straightforward to introduce a more reproducible environment at any time.
Currently the provenance tracking is fairly manual and relies on user annotations when running commands, though we have developed some automation helpers for specific cases like a LaTeX build. In the long run, we’d like to explore tracing filesystem access to automatically determine which files are used by a command.
Two surprises so far from our experience with this prototype:
Implicit build spec: “Build systems” like this usually have a “makefile” – a specification file that defines how outputs should be generated from inputs. But we realized during our design phase that the provenance information we were tracking made a makefile unnecessary. Once you’ve run a command to generate an output file, the implicit trace of provenance records the information that would ordinarily be explicitly written in a makefile. We’ve gotten feedback from scientists that this approach serves their needs well.
Provenance as map: We created the build graph as a quick way to see which files are out of date, but we’ve also found it surprisingly useful as a “map” for navigating a project’s contents. It’s easy to find the final PDF at the bottom of the graph. Pipelines of input into the paper are automatically organized above. Although the simple graph we’re showing now might become a tangle in larger projects, we plan to explore more ways to let authors map out their projects through provenance relationships.
FileWeaver shows a dependency graph between files.
Burrito, by Philip Guo and Margo Seltzer, tracks research programming activites on a Linux machine, including showing provenance relationships between inputs and outputs.
Burrito shows relationships between input and output files.
Our prototype shares the general idea of this prior work: that tracking and visualizing provenance can help people manage projects with complex file structures. But we’re building in a collaborative local-first editor built on Automerge rather than a desktop Unix environment, which opens up new technical opportunities to reimagine features like versioning and provenance.
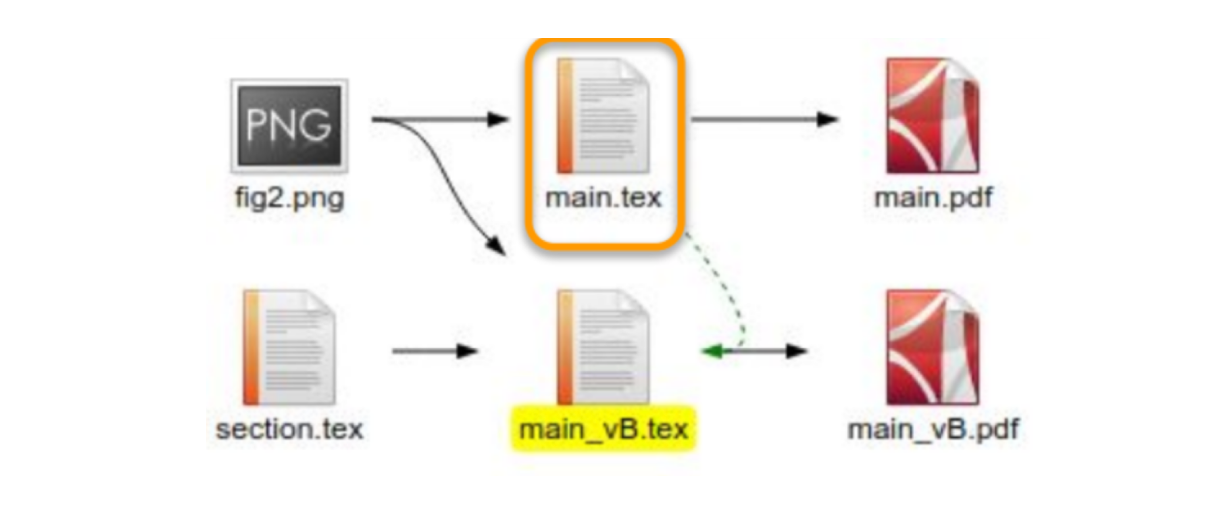
In our previous post, we explored interfaces for tracing provenance between inputs and outputs at the level of an entire file. But sometimes, it’s useful to see a more detailed view: fine-grained provenance that connects specific parts of one file with corresponding parts of another file.
Fine-grained provenance connects parts of a source artifact with corresponding parts of a build output
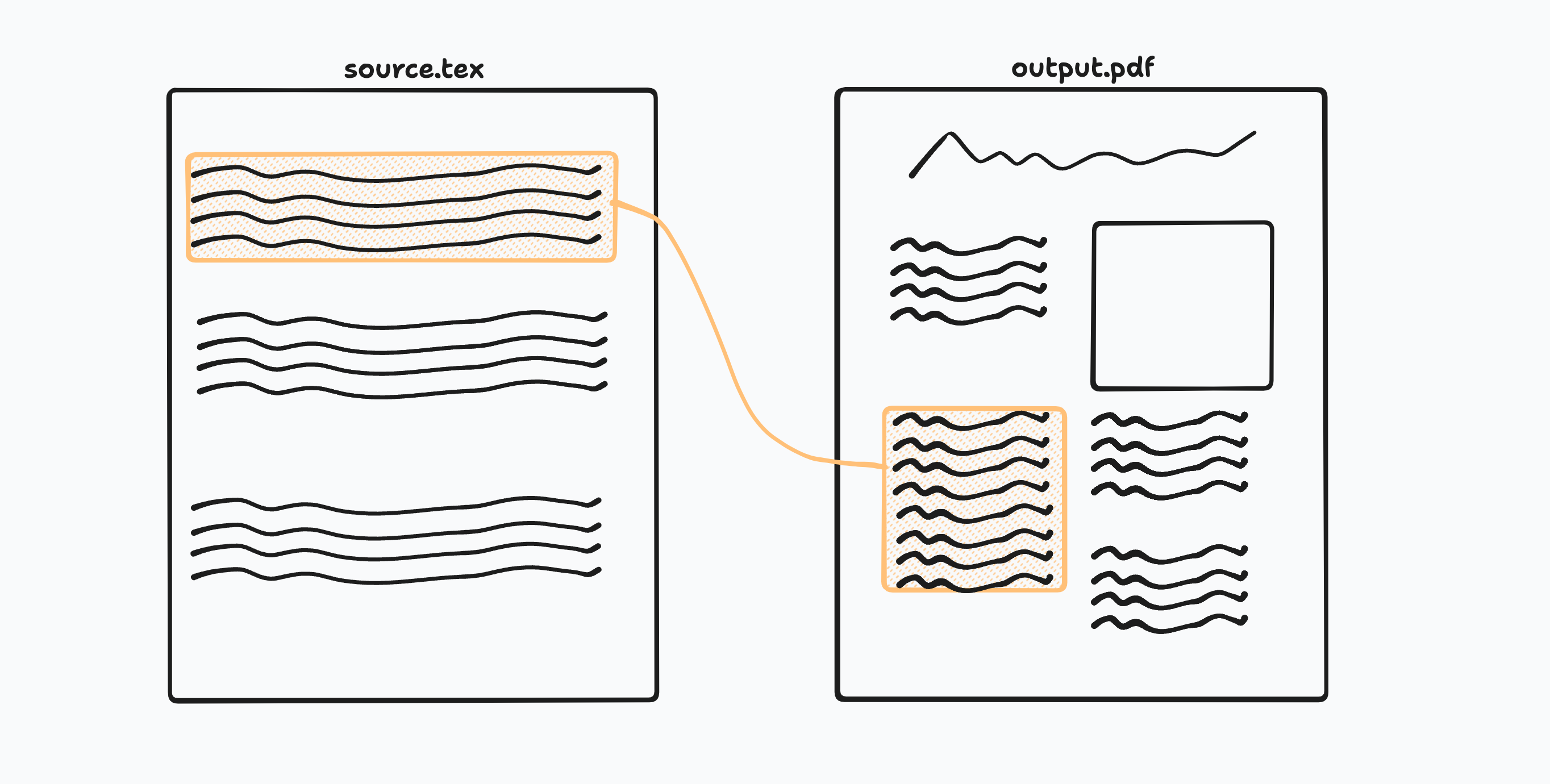
One example of fine-grained provenance is a feature found in some existing LaTeX editors: when a user is viewing a source file and a compiled PDF side by side, the interface can automaticaly scroll the PDF to show the location corresponding to the current location in the source file (and vice versa). Multiple researchers have told us they find this feature essential for keeping track of where they are as they edit.
Beyond “click to scroll”, what other interactions might use fine-grained provenance to help authors work across source and build files? And more broadly, how might fine-grained provenance grow from a one-off feature for LaTeX files to a universal primitive in a multimedia collaboration environment?
One interaction we explored was inline editing, where a user can click on text in the PDF and edit the source code underlying that text in a popup window:
We found that this workflow felt great for making small local edits while reading a built document, almost like editing a PDF directly.
We also explored mirrored comments, in which comments left on the formatted PDF are propagated to the corresponding location in the source file:
This allows a commenter to work on the PDF, while an author addressing comments can see them directly while editing source text:
Propagating comments also has a subtler advantage. Usually, comments on a PDF can’t be carried forward to future compiled versions of the paper, because comments are anchored to fixed positions while contents shift beneath them. But when comments are attached to source material, it’s possible to automatically move the comments to their new locations as the PDF evolves.
Finally, we considered a more speculative idea for organizing projects based on fine-grained provenance: what if the layout of a file could serve as a visual map for navigating the project structure? For example, a Python file used to create a figure would be placed by the figure it creates; in turn, the data file that it reads in would be located near the line of code that reads the file:
Using arrows between specific parts of a Python file and a PDF to indicate fine-grained provenance
So far, our interactive prototypes above have been built specifically for the combination of a LaTeX source file and an output PDF, but we’re intrigued by the possibility of generalizing the concepts to apply to various kinds of media and build processes.
We’ve previously described the pointer concept in our Patchwork environment, which defines how to point to specific parts of a document like an essay or a drawing. Fine-grained provenance could build on this pointer mechanism, if build steps produced a mapping from pointers in the source to corresponding pointers in the output.
Such a system would support our LaTeX prototypes, which were built using SyncTeX to compute mappings between LaTeX source lines and corresponding bounding boxes in a PDF. And it could also generalize to other kinds of mappings, like source maps generated by code compilers.
One challenge we’ve encountered on the path to a general provenance primitive is that the exact granularity and precision of provenance information can significantly affect the experience. For certain interactions like clicking to scroll to a corresponding location, a rough approximation suffices. But for interactions like inline editing or propagating comments, precision matters. In our initial experiences working with SyncTeX, we’ve already hit challenges with imprecise and inccurate provenance data; these limitations in the underlying metadata can lead to a confusing experience.
Overall, we think there’s great potential in interactions that use fine-grained provenance to move back and forth between source files and build products, crossing the boundaries of different media. We think fluid movements like these may be more natural in Jacquard than in the conventional world of siloed applications.
The Ink & Switch Dispatch
Keep up-to-date with the lab's latest findings, appearances, and happenings by subscribing to our newsletter. For a sneak peek, browse the archive.