Scientific papers straddle two worlds. They’re thoughtfully crafted prose documents, but they’re also computational documents containing data analyses and visualizations. Today, the prose and computational parts of a paper often live in different environments and tools, which causes friction for teams of scientists.
For instance, one scientist told us that he keeps chart-generation code in a git repo, but collaborates with coauthors in the web-based Overleaf tool. Every time a chart changes, he needs to manually drag files from his computer into the browser. Meanwhile, his collaborators have little visibility into the code and data that generate charts.
Other scientists have told us about difficulties staying oriented as they move between a paper and the data pipelines that feed into it. A paper’s LaTeX source refers to a chart PNG file… but wait, which data file and Python script were used to generate that PNG?
We wondered: what if one collaboration environment could host both the text of the paper and the data visualization code, making it seamless to edit them together? Here’s a prototype:
Using a provenance graph to navigate a project and automatically propagate updates
The demo shows a web-based collaboration environment with provenance — information about how computed artifacts were generated from source material. By keeping track of provenance, we know when an output file needs to be rebuilt, and we know how to do it. We can also use provenance to create a map of the project:
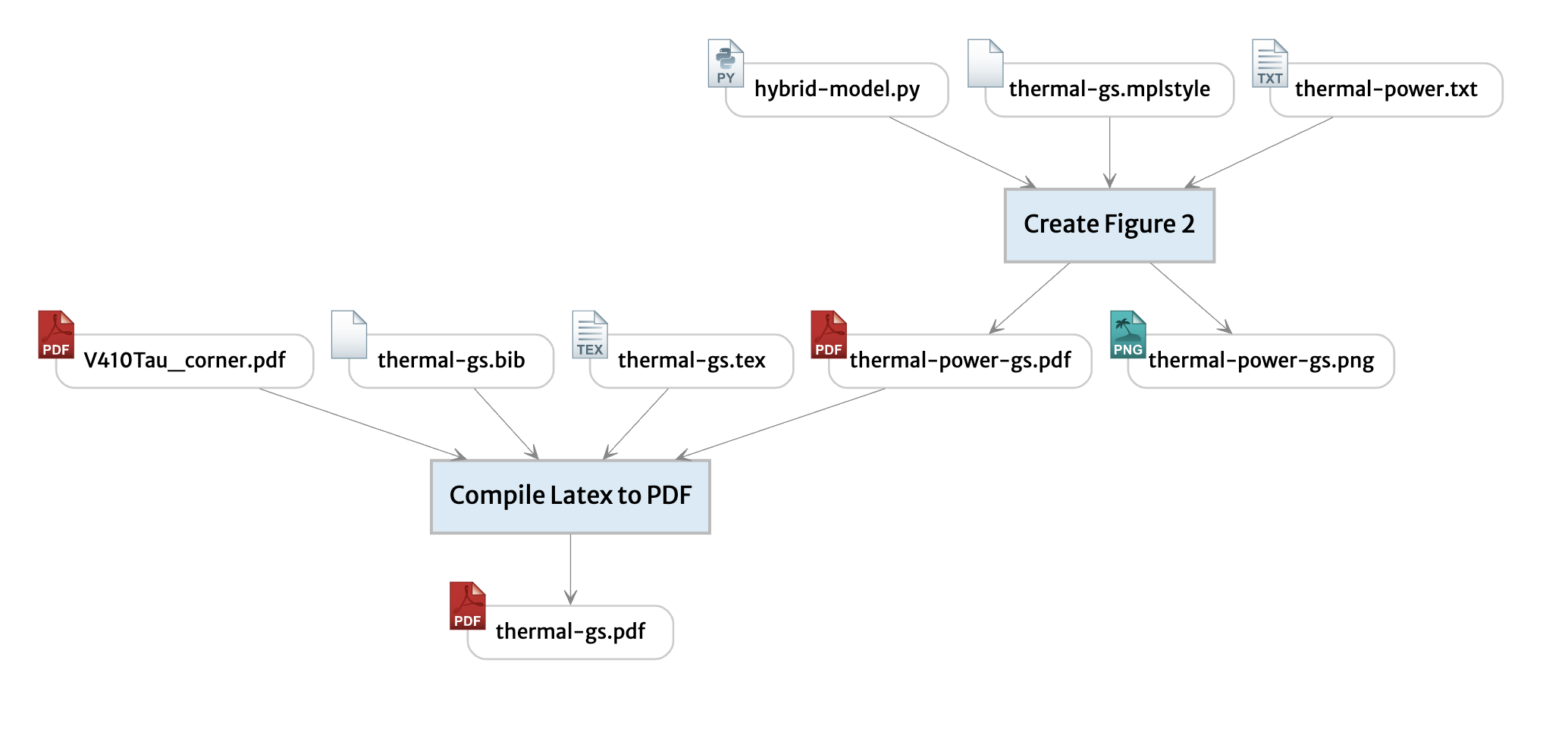
The build graph shows how files affect one another.
A core challenge we’re exploring in this prototype is how to integrate a collaborative web-based editor with the full power of running arbitrary computations on a Unix shell.
Behind the scenes of this demo, there is a watcher process which can be hosted on any computer, like a scientist’s own laptop or a cloud server. When the user requests a rebuild from the web interface, the watcher process detects the request, re-runs commands like the Python script or the LaTeX compiler, and syncs the results as well as provenance information back to the web view.
We think the ability to run the watcher process on any computer provides useful flexibility. At first, a scientist can easily try out computations without needing to initially make them portable or run them in a Docker container. At the same time, it’s straightforward to introduce a more reproducible environment at any time.
Currently the provenance tracking is fairly manual and relies on user annotations when running commands, though we have developed some automation helpers for specific cases like a LaTeX build. In the long run, we’d like to explore tracing filesystem access to automatically determine which files are used by a command.
Takeaways
Two surprises so far from our experience with this prototype:
-
Implicit build spec: “Build systems” like this usually have a “makefile” – a specification file that defines how outputs should be generated from inputs. But we realized during our design phase that the provenance information we were tracking made a makefile unnecessary. Once you’ve run a command to generate an output file, the implicit trace of provenance records the information that would ordinarily be explicitly written in a makefile. We’ve gotten feedback from scientists that this approach serves their needs well.
-
Provenance as map: We created the build graph as a quick way to see which files are out of date, but we’ve also found it surprisingly useful as a “map” for navigating a project’s contents. It’s easy to find the final PDF at the bottom of the graph. Pipelines of input into the paper are automatically organized above. Although the simple graph we’re showing now might become a tangle in larger projects, we plan to explore more ways to let authors map out their projects through provenance relationships.
Prior art
Our thinking on provenance tracking has been inspired by prior work, in particular two papers:
FileWeaver: Flexible File Management with Automatic Dependency Tracking by Julien Gori, Han Han, and Michel Beaudouin-Lafon, shows a dependency graph view of build tasks over a Unix filesystem:
Burrito, by Philip Guo and Margo Seltzer, tracks research programming activites on a Linux machine, including showing provenance relationships between inputs and outputs.

Our prototype shares the general idea of this prior work: that tracking and visualizing provenance can help people manage projects with complex file structures. But we’re building in a collaborative local-first editor built on Automerge rather than a desktop Unix environment, which opens up new technical opportunities to reimagine features like versioning and provenance.
Thanks to Will Golay for providing the code for the sample paper in the demo.