The Ink & Switch Dispatch
Keep up-to-date with the lab's latest findings, appearances, and happenings by subscribing to our newsletter. For a sneak peek, browse the archive.
2025 Mar 13
The last few lab notes have focused on the cryptographic components which support a local first access control system. Those being a capability based system for managing write access to documents, and a key agreement protocol for encrypting and decrypting writes (thus implementing read control). We now have to think about how to actually transfer this data between devices.
Alongside the Keyhive project we have also been working on a new sync protocol for Automerge. The existing sync protocol works well for a single document but it is common for Automerge applications to have thousands of documents. Furthermore, the sync protocol requires that both ends are able to read the document whilst one of the objectives of Keyhive is for the server to only have access to the encrypted data.
Solving all of these problems in one go is the job of Beelay (the name is inspired by the idea of Beehive being the relay for all the bees (peers) in the Keyhive).
Beelay is an RPC protocol which is designed to be usable over any transport which can provide confidentiality (in practice, HTTPS, WebSockets, or raw TLS). The intended usage is to create a local Beelay instance and then connect it to other peers, Beelay will then authenticate with the other peers and synchronise everything which each side thinks the other has access to.
Each message is authenticated by signing it with the Ed25519 key that the local node controls. To synchronise we first synchronise the Keyhive membership graph which each end has, this allows each end to determine what documents the other end should have access to. Then we synchronise the collection of documents to figure out which documents are out of sync, before finally synchroising each individual document.
It will be useful here to review how we intend to represent devices, people, and documents in Keyhive. In Keyhive there are two important kinds of principal: “groups” and “individuals”. An individual is identified by a single Ed25519 public key - which is immutable - whilst a group is a collection of other principals (groups or individuals) and can be updated by it’s members. One way we intend to use this is to represent a person (or more specifically their authority) as a group, with each of the persons devices being an individual member of the group. Key rotation can then be handled by adding a new individual to the group and removing the old one.
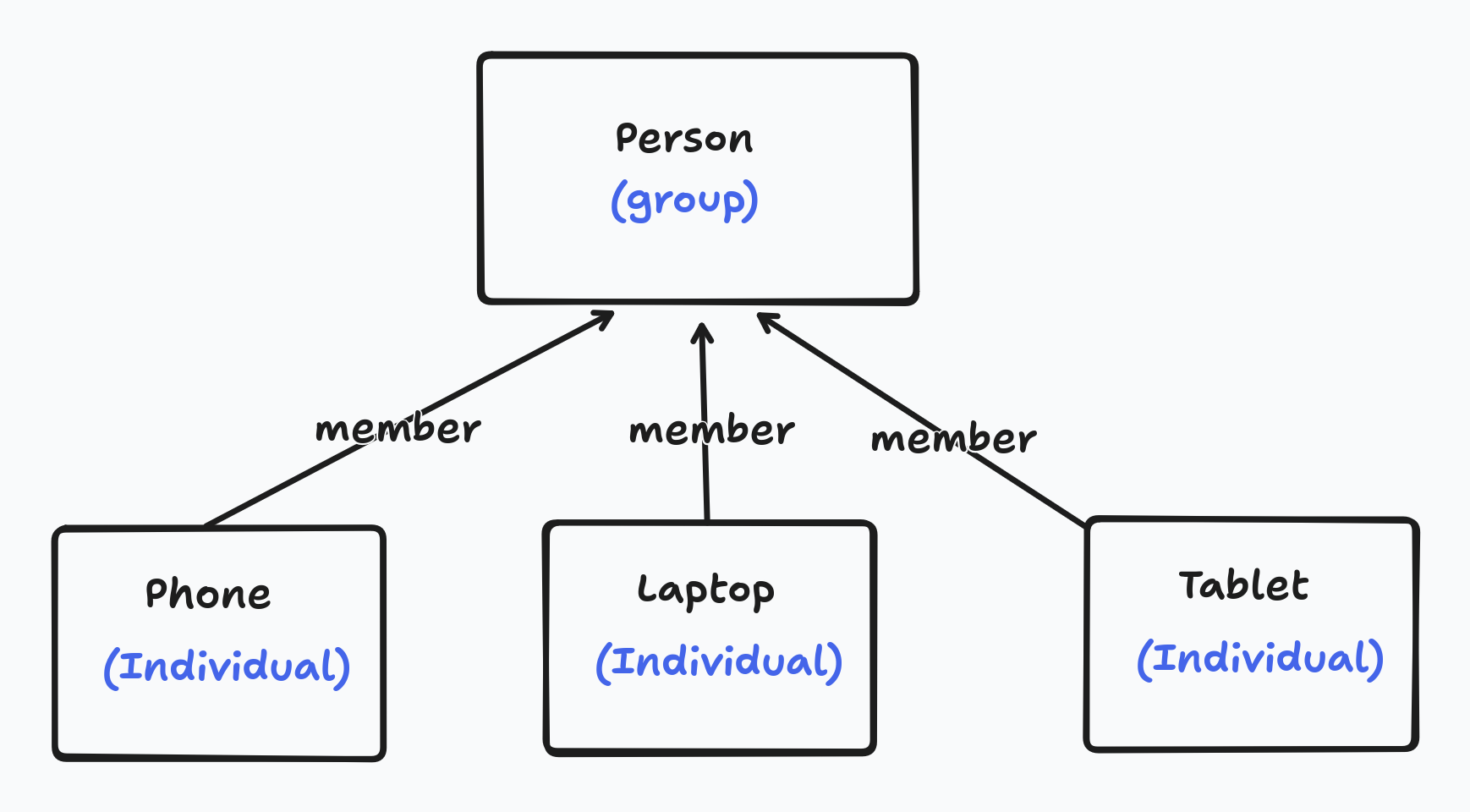
Groups can contain other groups. This means that we can represent as groups, where each member of the organisation is another group representing a person (or for that matter another organisation, such as a department).
Another useful aspect of this structure is that documents can also be represented as groups. This allows documents to have members which can access the document. For example, a document representing this lab note might add the Ink & Switch group so that all (transitive) members of the Ink & Switch group can read and write to it. Documents can also add other documents which represents “folder” style relationships. The “lab notes” folder document (which is also a group, because all documents are) might contain all the lab notes and have the Ink & Switch as a member.
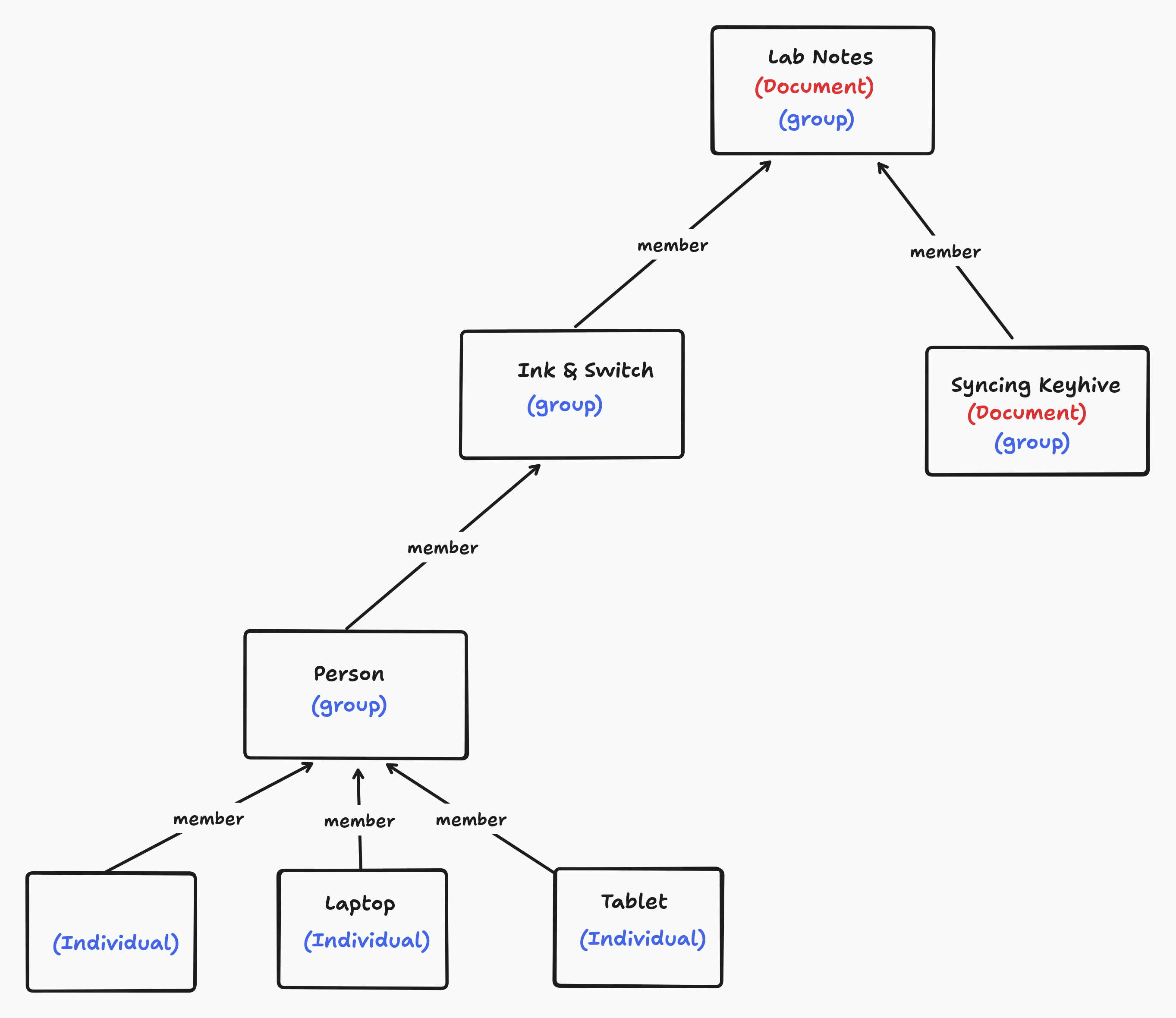
What this all means for the sync protocol is that any given peer is represented by an “individual”. The task of authentication is to ensure that each end knows what Ed25519 public key the other end is using so that we can relate that individual key to the Keyhive membership graph.
One solution which might seem obvious here is to rely on an authenticated TLS session. While we use TLS for confidentiality, and the browser itself authenticates the server, our application also needs to know about the server’s public key. Unfortunately, the browser doesn’t expose this information to the application context; there is no way in the browser to obtain the connection’s TLS certificate. We don’t just need to know that a connection is secure, we need to know the public key of the other end in order to use it for access control decisions and so on.
Given that each peer is represented by a public key, the simplest possible authentication scheme would be to sign each message. I.e. a message might look like this:
type Envelope = {
message: Uint8Array,
signature: Signature,
sender: PublicKey,
}
type PublicKey = Uint8Array
type Signature = Uint8Array
To authenticate a message we check that the signature is valid over the message, then we know that the other end is the individual represented by the given public key. There are two problems with this, person in the middle (PITM) attacks, and replay attacks.
A good example of PITM attack on this protocol would be a phishing based attack. Imagine an application which allows users to input the URL of a sync server to sync from. Let’s say an attacker creates a sync server at a familiar looking URL, such as wss://sync.automege.org (note the misspelling) and convinces the user to enter this URL into their application. The attacker can now intercept all messages intended for the real sync.automerge.org server and forward them on to the sync server. This means the attacker can read all the messages and even modify messages sent back to the client.
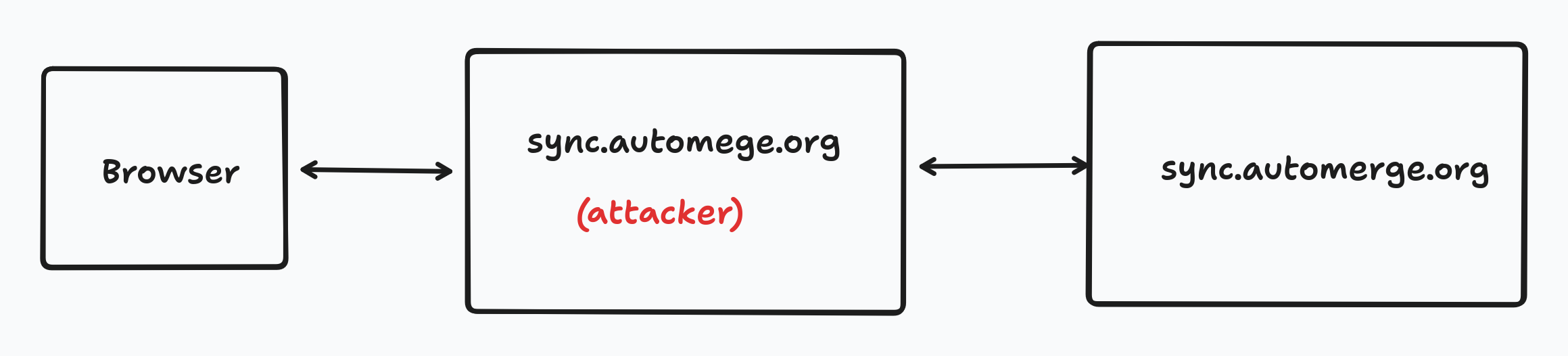
The fundamental problem here is that the message is bound to the sender but not to the receiver. We can solve this by adding an “audience” field to the message.
type Envelope = {
message: Message,
signature: Signature,
sender: PublicKey,
}
type Message = {
payload: Uint8Array,
audience: PublicKey,
}
This doesn’t quite solve the problem above though. At this stage we only have a URL, we don’t have a public key for the server. To solve this we allow the audience field to either be a public key, or the URL we are addresssing. In this case the audience would be sync.automege.org. This means that when the PITM forwards the message to sync.automerge.org the real server can check and see that the audience doesn’t match sync.automerge.org and reject the message.
This works because the connection is being made over TLS, which binds the network transport to the hostname, ensuring that whoever is at the other end, they definitely control sync.automerge.org. Beelay is designed to work over arbitrary transports though, in other network setups such as P2P transports you will need to obtain the public key of the receiver out of band.
In a replay attack an attacker is somehow able to intercept messages and store them, and then later replay them to the server. To mitigate this we add a timestamp to the message and then reject messages which are older than some validity window that accounts for latency plus a clock skew grace period — e.g. 5 minutes.
The main issue with this scheme is that the clocks of two peers might be out of sync by arbitrary amounts of time. Soft locking the sync system due to clock sync issues is not acceptable. To solve this, when a peer rejects a message due to an old timestamp, the rejecting peer sends their current timestamp along with the rejection message. This allows the sending peer to determine the drift between their local clock and the remote clock and adjust the timestamps on the messages they send, and account for it during this session.
Altogether then, our messages look a bit like this:
type Envelope = {
message: Message,
signature: Signature,
sender: PublicKey,
}
type Message = {
payload: Uint8Array,
audience: PublicKey | string,
timestamp: number,
}
To authenticate a message we check that the signature is valid, that the audience is either our public key or the hash of our hostname (or some other string which is bound to the recipient in some way) and that the timestamp is new enough.
Once we are authenticated, we need to determine what each side thinks the other should have access to. This means that we need to sync the Keyhive “membership graph”. This is the graph of groups and individuals which represent devices, people, organisations, and documents.
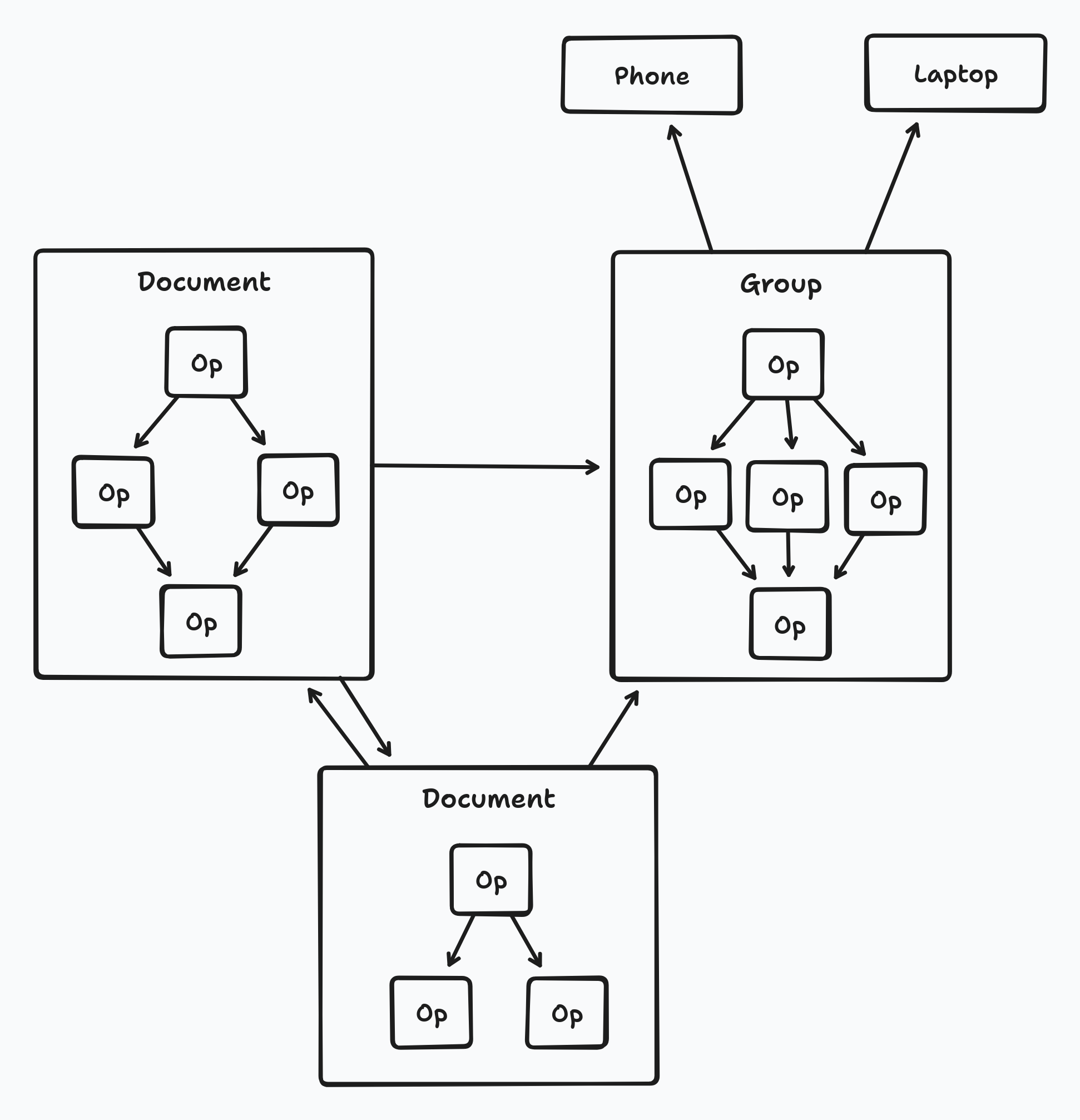
The membership graph is a directed graph of “operations” where each operation either creates a new node, delegates access to some other node, or revokes access. Unlike Automerge documents (which are also graphs) the membership operation graph is very shallow and wide, and the linked groups and documents can have cycles. There are many approaches to this problem, but it becomes much simpler if we frame it as set reconciliation, where each side has an unstructured set of operations and needs to figure out what operations the other side has that it needs (i.e. the delta between the two sets). We will encounter a very similar problem later, when we sync the collection of documents. In both cases we use a construction called Rateless Invertible Bloom Lookup Tables (RIBLT) to solve this problem.
RIBLT is described in detail in this paper, what I will describe here are the important properties that the scheme gives us.
RIBLT is a set reconciliation protocol, which means there are two peers who have some possibly overlapping set of things which they want to have the same view of. I.e. after the protocol completes each side should have the union of the things each started with.
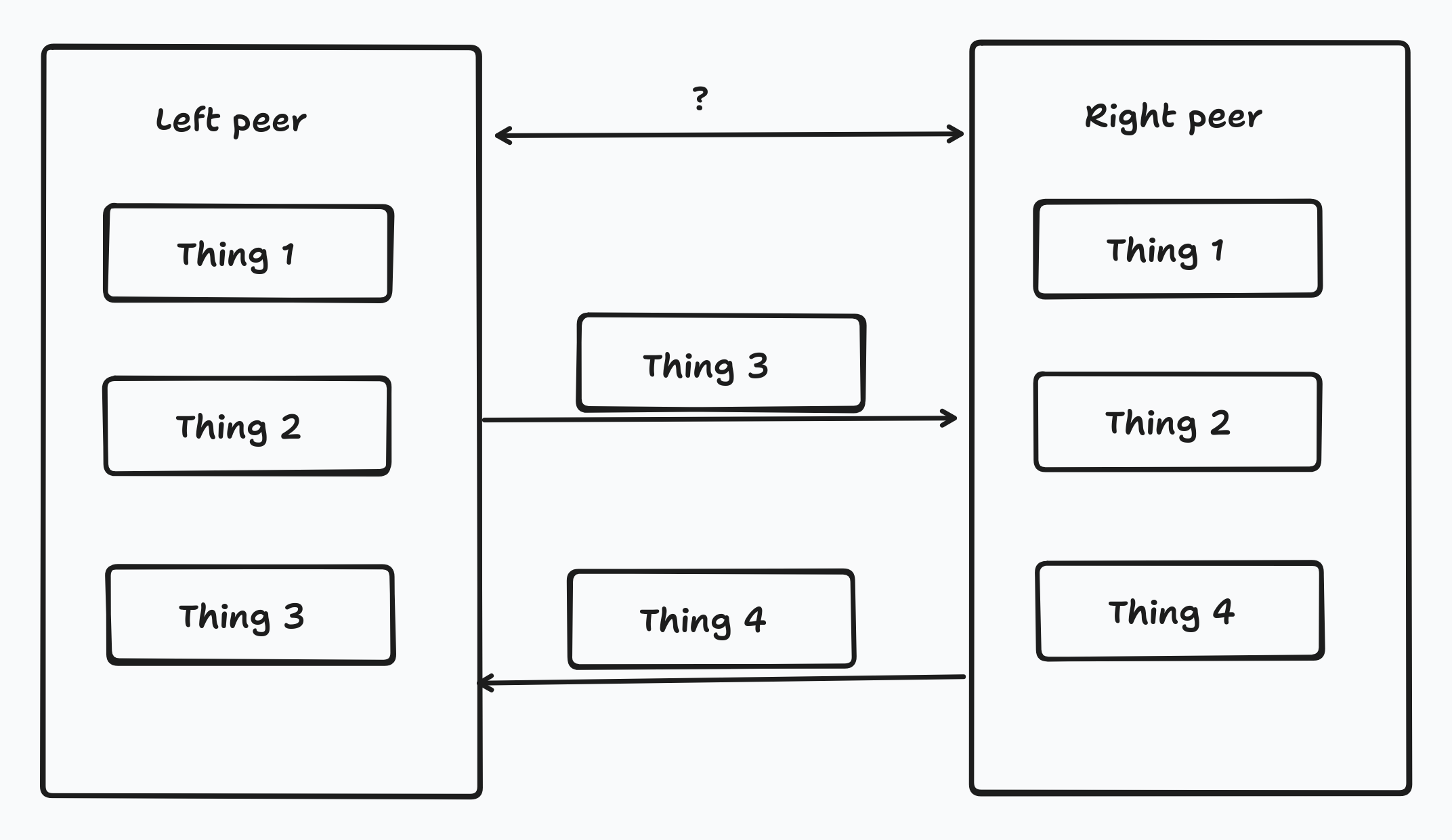
RIBLT solves this problem by having each side encode it’s set of things into a set of hashes and then generate a set of special “symbols” which one side sends to the other.
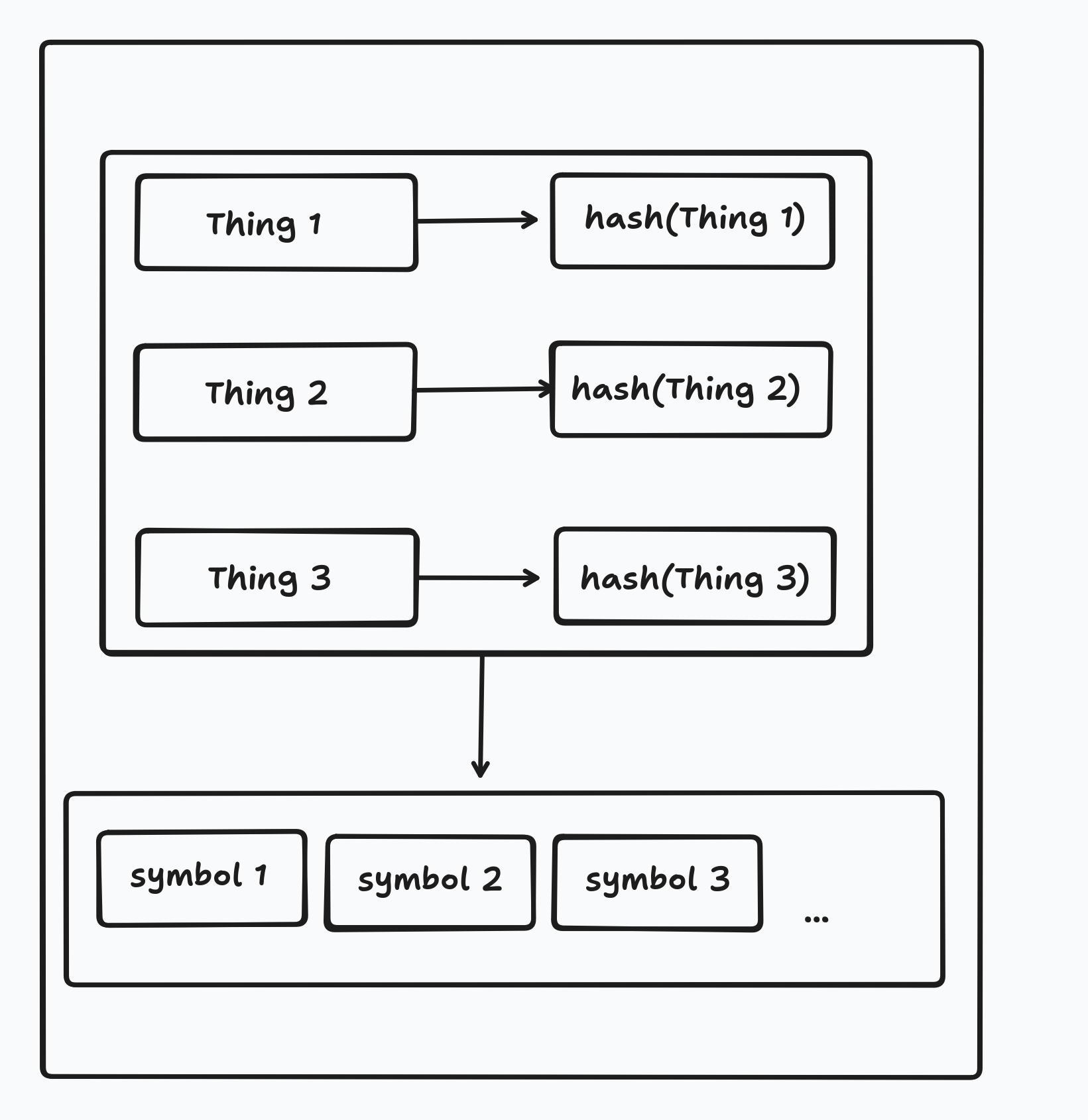
These symbols are structured in such a way that once the receiver has received enough of them they will be able to decode the symbols into the set difference.
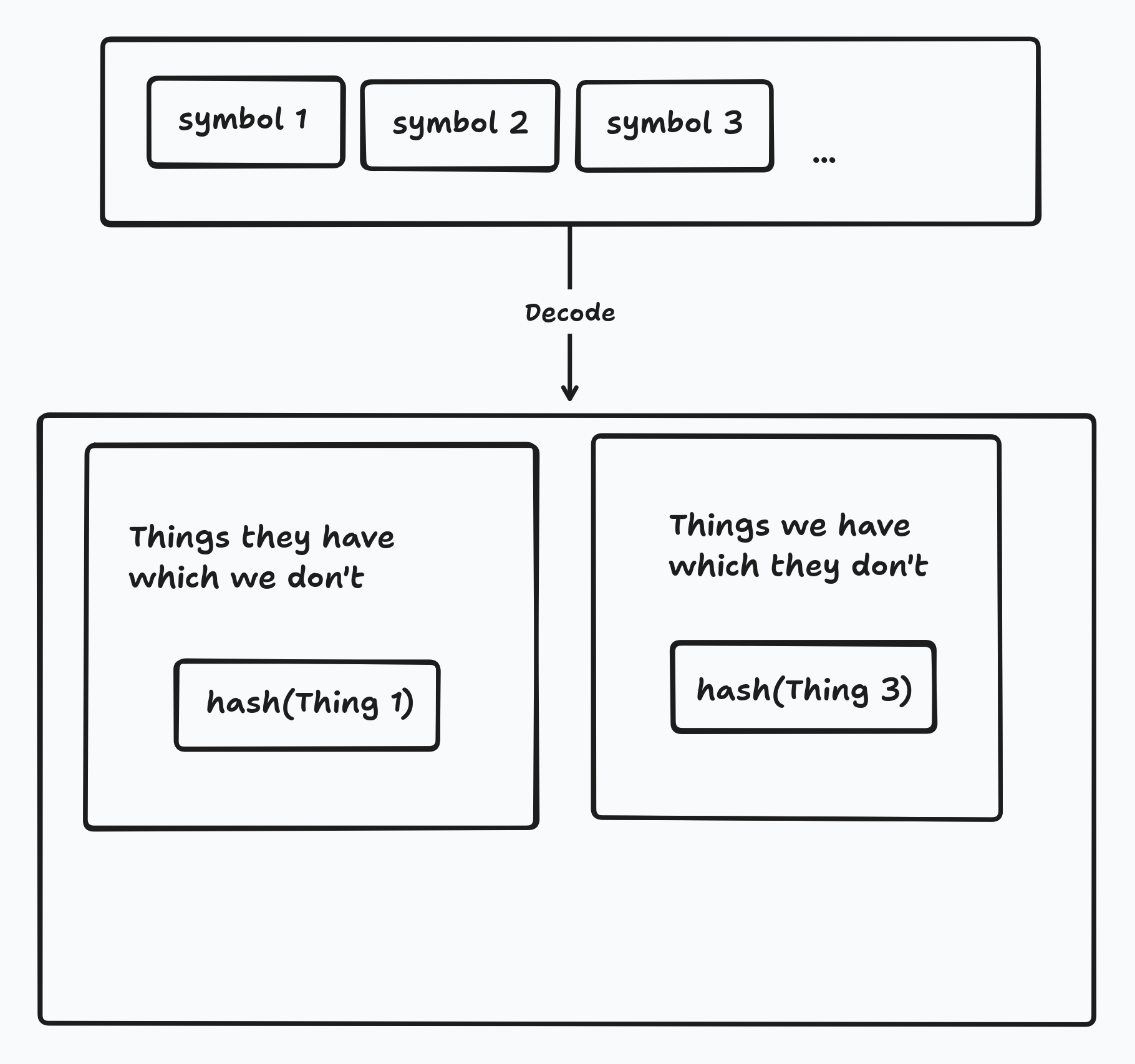
The details are a bit fiddly but the really important part is that the number of symbols which must be sent is proportaional to the set difference between the two peers. Specifically, the number of symbols sent ranges from 1.7x (for small sets) down to 1.35x (for large sets) the set difference.
For example, If we have one billion items each, but only five differing items, we can reconcile in 5 * ~1.5 = 7.5 symbols. The symbols themselves are (in our case) 32 bytes long, so we can reconcile a billion items in 240 bytes.
The other important part is that the result of decoding is the set of hashes - not the things themselves. In fact, we can use any fixed length array which uniquely represents the thing.
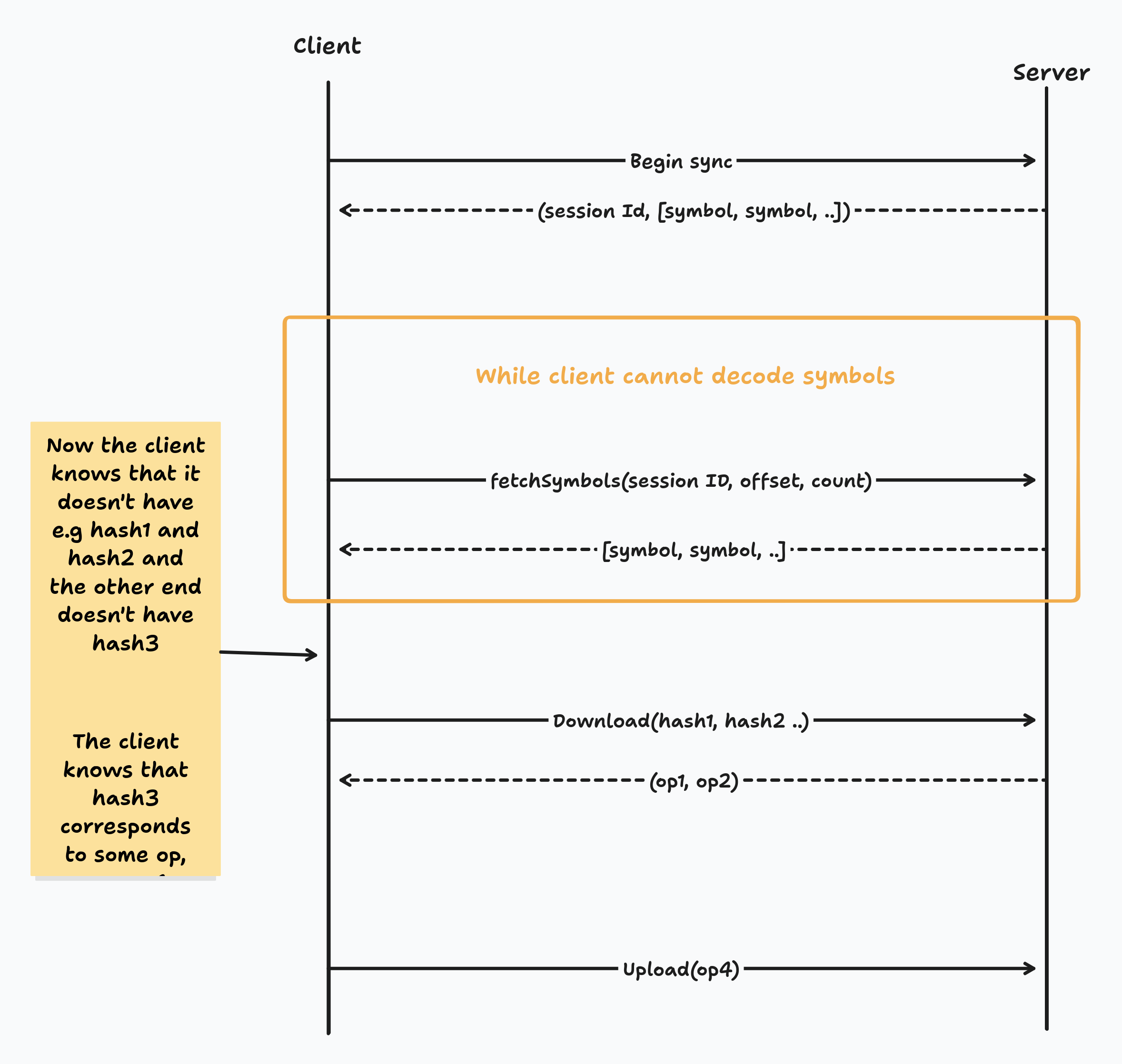
So, we use RIBLT sync to synchronise the membership graph. The process is mostly driven by the client (in the peer to peer case we arbitrarily choose that the peer who initiated the connection is the client).
First, the client sends a request to the server to begin membership sync. The server stores a pointer to the current set of ops which it thinks the other end needs and then responds with a session ID to identify this sync session, and the first 10 symbols of the RIBLT sync.
The client now receives the first 10 symbols and attempts to decode them. If they are able to decode then they are done and they know the set difference, otherwise, they send a request for the next 10 symbols, using the session ID to specify which state they are syncing with.
Eventually the client knows the set difference in terms of hashes of operations which only the server has, and operations which only the client has. Finally, the client requests the missing operations by sending their hash, and uploads the symbols which they believe the server is missing.
At this point each end has determine what documents it thinks the other should have acces to. The next step is to determine which documents are out of sync. To achieve this we use RIBLT sync again, this time instead of the set we are synchronising being the set of membership operations it is the set of (document ID, state) pairs, where state here is a hash of the document state.
There are two components to the document state which we care about for the purposes of synchronisation. One is the heads of the Automerge document - the document content is encrypted but we keep the hashes of the Automerge commit graph outside of the encryption envelope, so the sync server knows the heads.
The other piece of state are the BeeKEM operations for the document. Recall that BeeKEM is a continuous group key agreement (CGKA) protocol which allows peers to concurrently decide on what keys to encrypt content to. We need to have the latest CGKA ops in order to be able to decrypt the document content.
How do we form our RIBLT symbols then? One way would be to make each symbol hash(document ID, document heads, cgka ops). Then, once we’ve performed RIBLT sync we make another network call to convert each symbol into the document ID which is out of sync. However, we can do a little better than this. Recall that the RIBLT symbol is just any fixed length byte array, and document IDs are a 32 byte array. This means that instead of a hash for the symbol, we use (document ID, hash(heads, cgka ops). This means that once we have decoded the symbol we already know what the document ID is for the symbol in question without doing any more round trips.
The process for actually running this sync then is similar to the membership sync. Using the session ID from the membership sync the client fetches new document symbols from the server until it is able to decode the first symbol it received, at which point it knows which symbols are out of sync.
By this point we have a list of document IDs which are out of sync. We now have to sync the CGKA ops and encrypted commit graph for each document. For the CGKA sync we can use our old friend RIBLT sync to sync the set of CGKA ops, but for the document content we need to do something a bit different because we want to be able to take advantage of the bandwidth gains we get from compacting Automerge documents.
The set we are synchronizing here is the set of CGKA ops for the document. We use the hash of each op to create our RIBLT symbols. As with other RIBLT syncs, the client requests symbols from the server until it is able to decode it’s first symbols at which point it knows what ops to upload and what ops to request.
Syncing the document content is more complicated. Initially it might seem that we could just use RIBLT sync again where the symbols to sync are the commit hashes of the commits in the Automerge commit graph. This would certainly work, however, it would use a lot of bandwidth. Automerge commits are frequently made for each keystroke, adding a 32 byte hash for each keystroke would be very expensive.
This is a specific instance of a general problem which is that naive encodings of the Automerge commit graph contain enormous amounts of metadata overhead. We have a compact binary encoding which reduces this overhead to around 10% over the underlying data. What we need is a way to use this data in the sync protocol.
In the current sync protocol this is not a problem, the sync server has the plaintext in memory and so it can compact the document on the fly when a new peer comes online. For Beelay this isn’t an option because the server only has the ciphertext. What to do?
We have come up with a simple protocol for this which we call “sedimentree”. The idea is that every so often we compress ranges of the commit graph into chunks and we do this recursively, so that every so often smaller chunks get compressed into larger chunks. We do this in such a way that older (i.e. closer to the root of the commit graph) end up in larger and larger chunks as time goes on. This forms a tree structure, with older chunks being closer to the root of the tree - hence sedimentree, with chunks being like layers of sedimentree rock.
Choosing the boundaries of the chunks is a little fiddly because we need to do it in such a way that peers with different sets of changes still agree on what should go into each chunk. We do this by using the number of trailing zeros in the hash of a commit as the boundary. There are more details on this here.
The end result of this structure is that we can sync the document in two steps:
Overall then sync looks like this:
One thing which may be concerning here is the number of round trips. We should especially worry about this in the common case where only one document has changed
We should be able to simplify this. One the initial message when we begin membership sync we can send the clients first 5 (say) membership RIBLT symbols and first 5 collection state symbols. In the common case the server will be able to decode these symbols (because only one document has changed) and immediately determine which document has changed, then the server can send back a response with the sedimentree summary for the changed document and the first 5 symbols of the server CGKA RIBLT state. The client will in most cases be able to determine if any CGKA ops are missing and immediately download any missing document state.
Thus in the common case we can sync graph updates (auth, content, etc) in just two round trips.