Keyhive is a project exploring local-first access control. It aims to provide a firm basis for secure collaboration, similar to the guarantees of private chat but for any local-first application.
In this lab notebook, we’ll share snippets of our findings as we explore the problem space and prototype potential solutions.
The entries start from the beginning, but you can jump to the most recent post: 05 · Syncing Keyhive
As the local-first ecosystem matures, the contexts that local-first applications fill has also expanded. Local-first emphasizes collaboration, but the constraints on an application are different if you build an application for you and a handful of friends versus delivering a team-oriented product. Your data not being viewable or editable by everyone in the world is a basic requirement of applications ranging from planning a surprise party, corporate meeting notes, book drafts, and legal contracts.
Today’s most common access control patterns assume a central server. While cloud auth tools are forever developing, generally speaking existing tools for cloud auth are very mature. Doing access control without a cloud auth server requires rethinking the underlying mechanics of how auth works. Keyhive is an attempt to do secure and efficient local-first auth while retaining the user experience found in familiar applications like Google Docs, Dropbox, GitHub, and Discord. We believe that these are table stakes for the next generation of local-first applications.
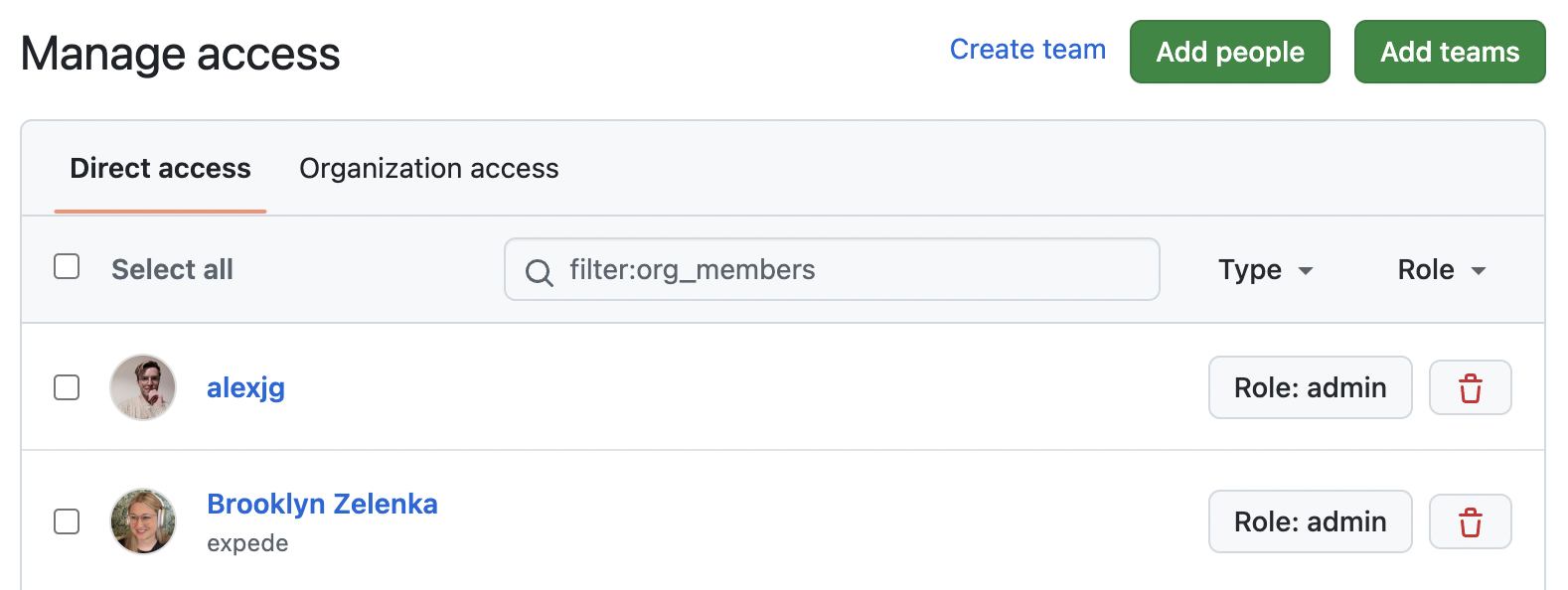
A GitHub repository permissions page
We’ve seen user-agency principals successfully applied to other contexts. Signal popularized end-to-end encrypted chat while retaining much of the convenience of less-secure messaging applications. We find ourselves asking “what would Signal for documents look like?”
Least Surprise
Unlike a cloud auth system which can depend on the network to keep data hidden behind a web API, local-first runs a complete copy of the application at each replica. What are the correct bounds on access control when everyone has direct access to all of the content? Ultimately access control is about collaboration. Collaboration and access control can be seen as two sides of the same topic: who do you want to collaborate with, in which ways, and for how long?
CRDTs try to merge data in the least surprising way possible. For example, concurrent text will merge to produce the same data on all replicas, but the resulting paragraphs may not make sense next to each other. Users then fix these semantic errors manually. We believe that this is a major improvement over the user experience of something like Git, which often gets stuck and demands user intervention.
The equivalent situation exists for concurrent access control, but the stakes are higher. Preventing your friend from learning that you’re planning a surprise party, or opposing legal councel from altering your case prep are both important, and it should be clear how they will behave despite any underlying concurrency. The behavior of an access control system should be as clear to the end user as possible. Since there is no single source of truth about who can do what at any given time, the rules themselves need to be straightforward.
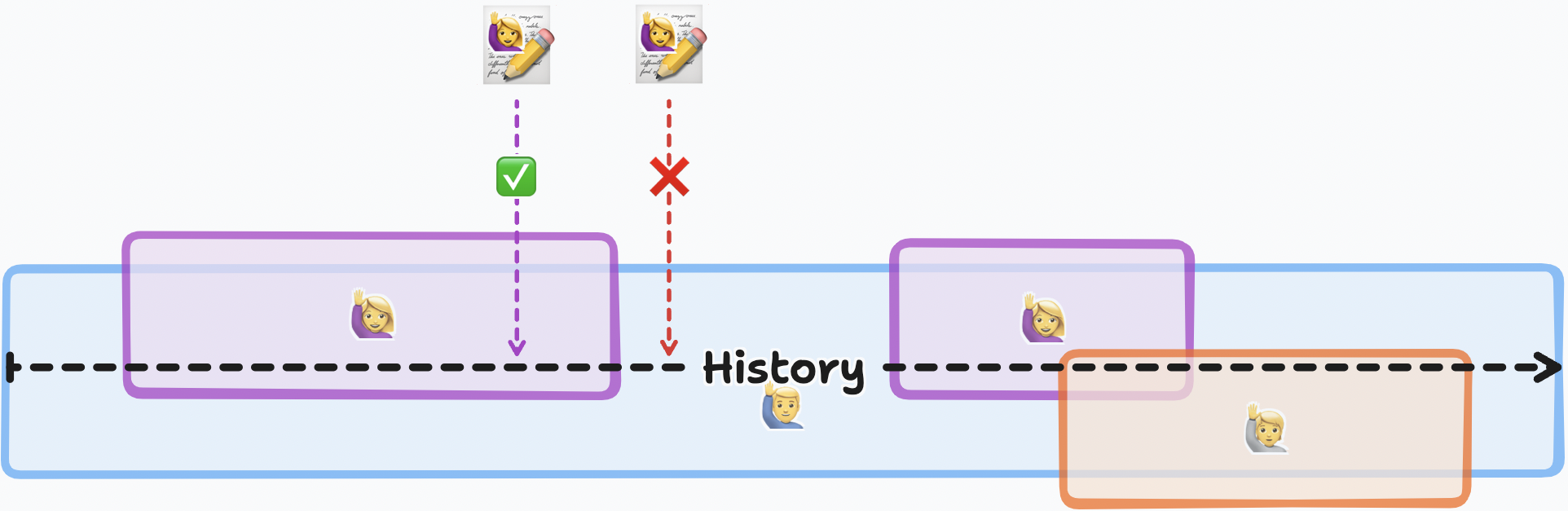
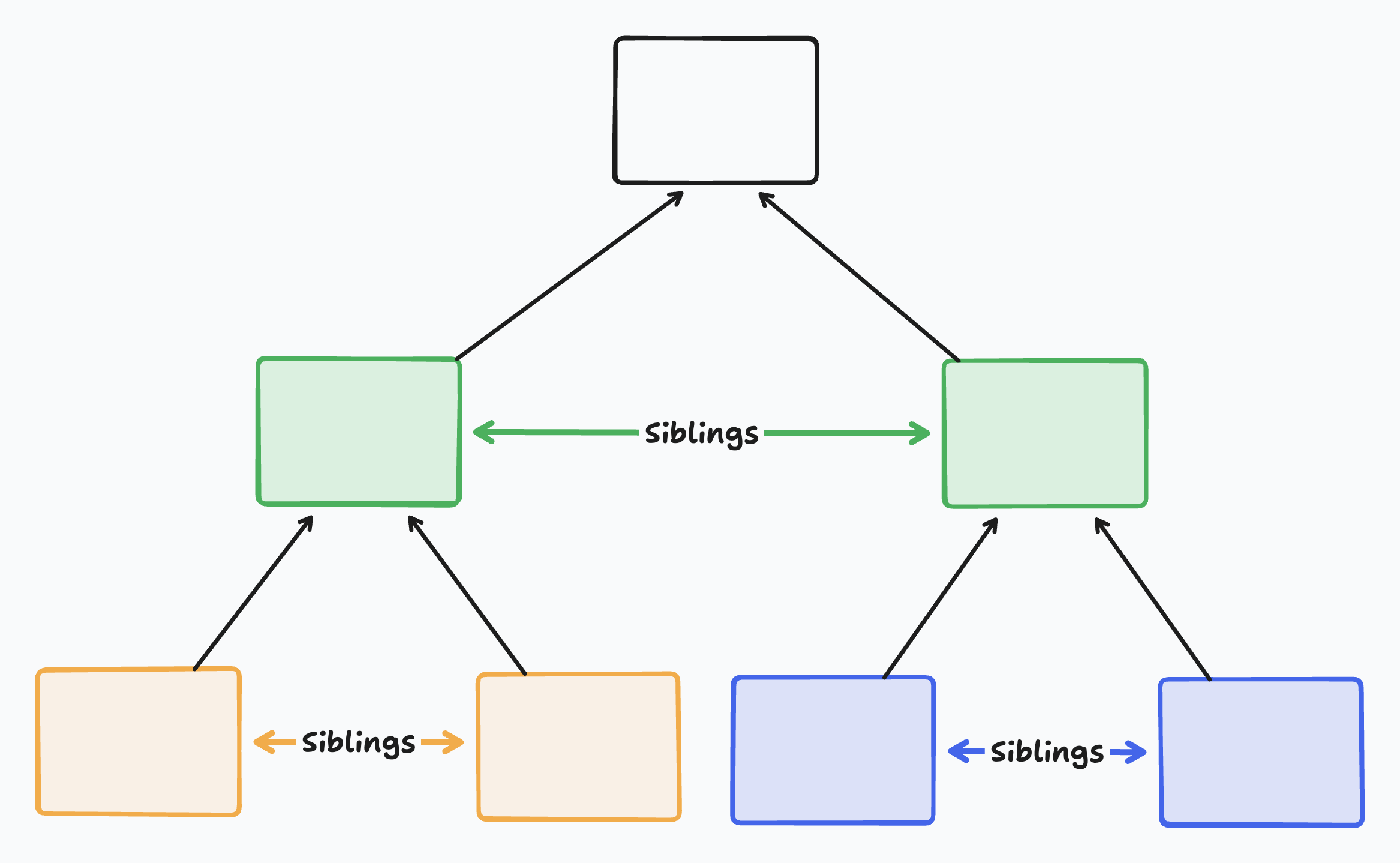
Ranges of authorization (and revocation) over time. Here 🙋♀️ is added, removed, and re-added later. Some of 🙋♀️’s updates are not materialized based on where they’re ordered in the document history.
Out of Obscurity
Often local-first applications today depend on “security through obscurity”. For example, by default you can write into any Automerge document that you know the document ID for. This style is sometimes called “Swiss number” or “Rumpelstiltskin” security. It works as long as the document ID is only ever shared with people that you want to collaborate with, your security is all-or-nothing, and you never want to later remove someone from a document. If the document ID leaks (e.g. someone posts it to Bluesky), then the document is world-writable.
In lieu of a widely-adopted1 purely local-first access control system, some teams have tried leveraging existing auth methods by routing updates through a cloud auth server (e.g. OAuth login and auth logic in a server). Others have opted to emphasize decentralized user agency by using a blockchain to store access control policies. Both of these approaches require a network connection in order to check if an update is valid, which is not local-first. Bringing access control features to a local-first context requires rethinking how authority flows between nodes.
What we want is a system that retains the best of the above: the self-certification of Rumpelstiltskin, the power of auth servers, and the user agency of decentralized solutions. Following the definition of local-first, applications should accept updates after arbitrarily long periods of disconnection. Extending that requirement to access control means the ability to revoke access or have finer grained control (e.g. read vs write) requires tracking who has authorization to do what, and at which point in the document’s history.
Today’s cloud services have very mature access control features. These systems depend on a key architectural detail: they are able to rely on encapsulation by taking advantage of the network boundary. Since data is not available to read or write directly by the client, a privileged guard process is able to apply arbitrary access control rules. This process retrieves and/or mutates data on behalf of clients.
This power unfortunately comes at a price: since auth is on the hot path of every request — and generally depends on a central single-source-of-truth auth database — authorization at scale often bottlenecks overall application performance. And yet, an attacker that is able to bypass the auth part of the request lifecycle has unmitigated access to arbitrarily read, change, or delete the application’s data. This is to say nothing of the complexity of building, deploying, and maintaining cloud architectures to get that network boundary in the first place!
For local-first software to be successful in many production contexts, it needs to provide similar features without relying on a central authorization server. The local-first setting does not have the luxury of a network boundary: access control must travel with the data itself and work without a central guard.
There are also some tricky edge cases due to causal consistency. What should happen to honest operations that causally depend on content that’s later discovered to be malicious? What is the best strategy to handle operations from an agent that was revoked concurrently, especially given that “back-dating” operations is always possible. If a document has exactly two admins (and many non-admin users), what should happen if the admins concurrently revoke each other (for instance, one is malicious)?
To address the above challenges, we’ve started work on Keyhive: a project focused on local-first access control. Our goal is to design and build a production ready instance of such a system which is general enough for most local-first applications.
Audience & Application
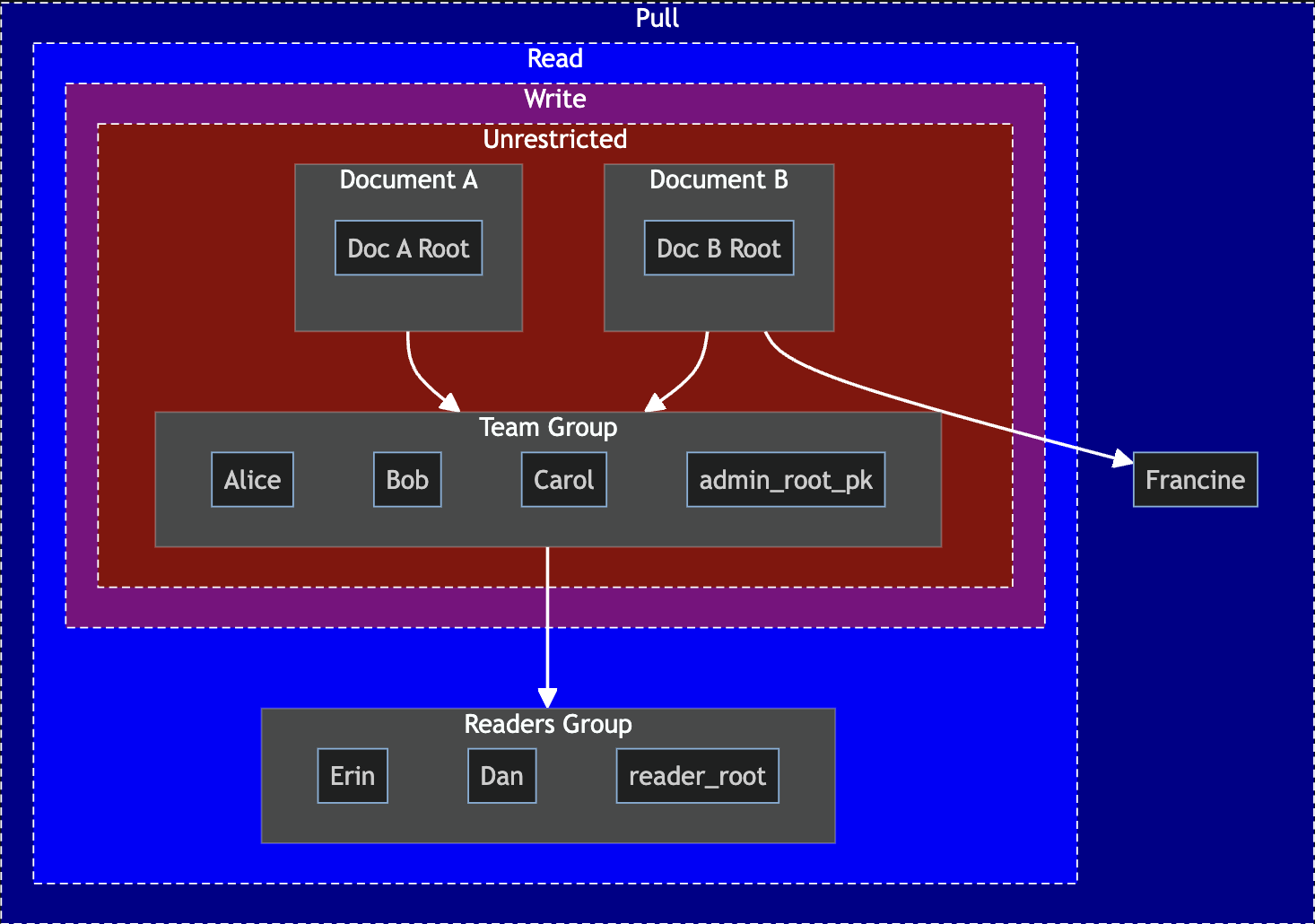
To date, the local-first ecosystem has primarily used a purely pull-based model where users manually decide which changes to accept. This approach is often sufficient for personal projects: each user can manually decide which peers to connect to and which changes should be applied. On the other hand, many production contexts have lower trust, require higher alignment, and are ideally low touch enough so that it’s not up to each person in a large organization to separately and manually infer who to trust. As a rough north star, we’re keeping the following use cases in mind:
Publishing (publicly visible data with restricted edits, like a blog)
Journalists & activists: small-to-medium groups, high risk
Cryptography has a reputation for being slow, especially if there’s crypto-heavy code running on low-powered devices. To have a performance margin that can cover a large range of practical use cases, Keyhive aims to run efficiently over at least ten-of-thousands of documents, millions of readers, thousands of writers, and hundreds of admins/superusers.
Since authorization, authentication, and identity are often conflated, it is worth highlighting that Keyhive deliberately excludes user identity (i.e. the binding of a human identity to an application’s identifier like a public key). In our initial community consultations we found that there are many different identity mechanisms that developers downstream of Keyhive would like to use. As such, we’re designing the system to be decentralized and secure, and leave name registration/discovery and user verification (e.g. email or social) to a future layer above Keyhive.
The following are left out of our design goals:
Constraining downstream applications to use a small predefined set of policies or roles
Interactive protocols (since local-first must work under network partition)
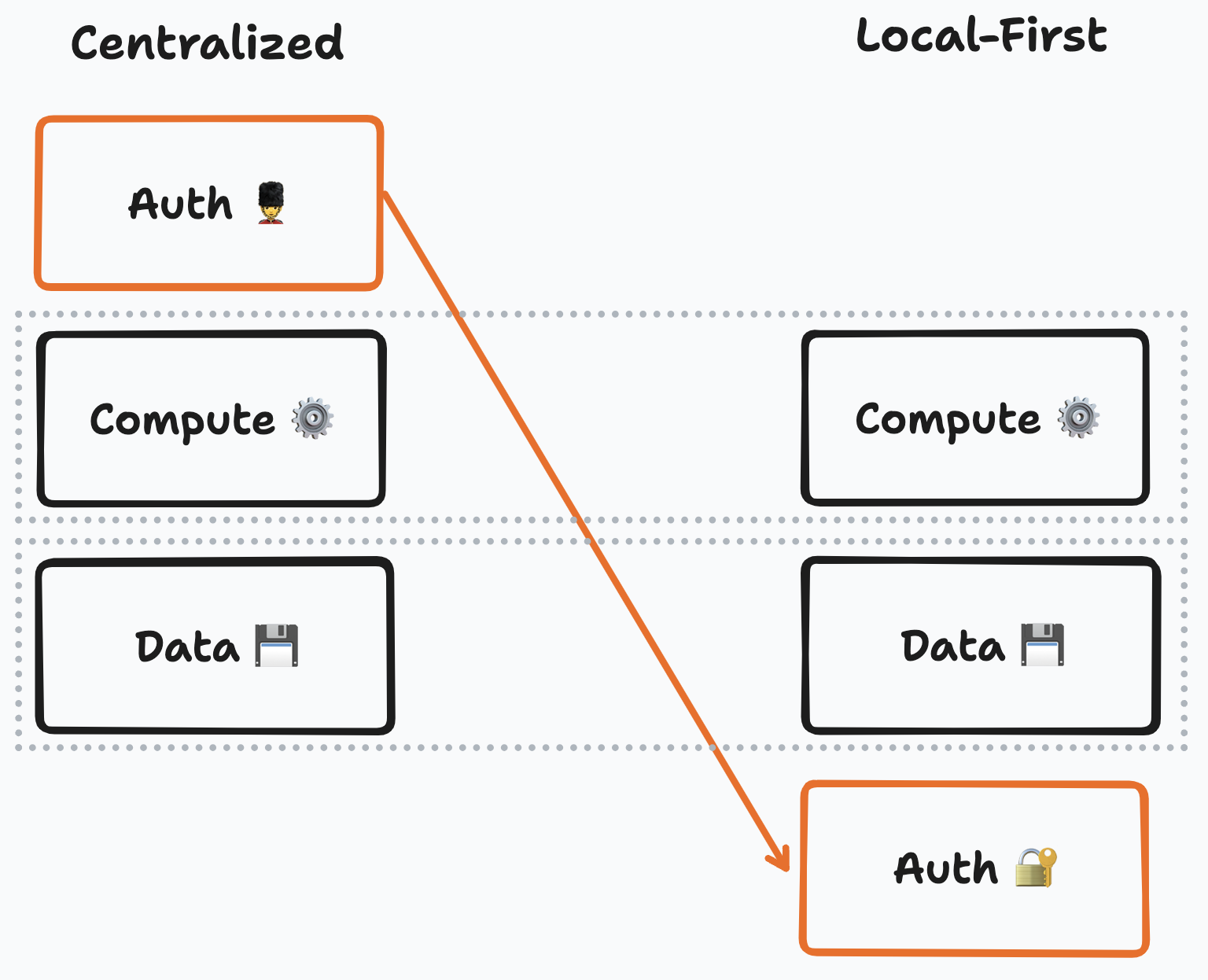
Most client/server backends place data at the bottom, and compute over it. In that model, auth is just another kind of computation. Leaving access control to a central process is not possible in a local-first context. In our context, the auth layer must act as a foundation.
Static authorization typically impacts the design of all other layers of a project. As an intuition, the storage layer will need to support data that is encrypted-at-rest, and so its design has a dependency on the auth layer. This means that since the design of an authorization mechanism may impose downstream constraints, its design should consider such potential impacts on the design of the rest of the stack. As much as possible, this project attempts to minimize imposing such constraints on other layers.
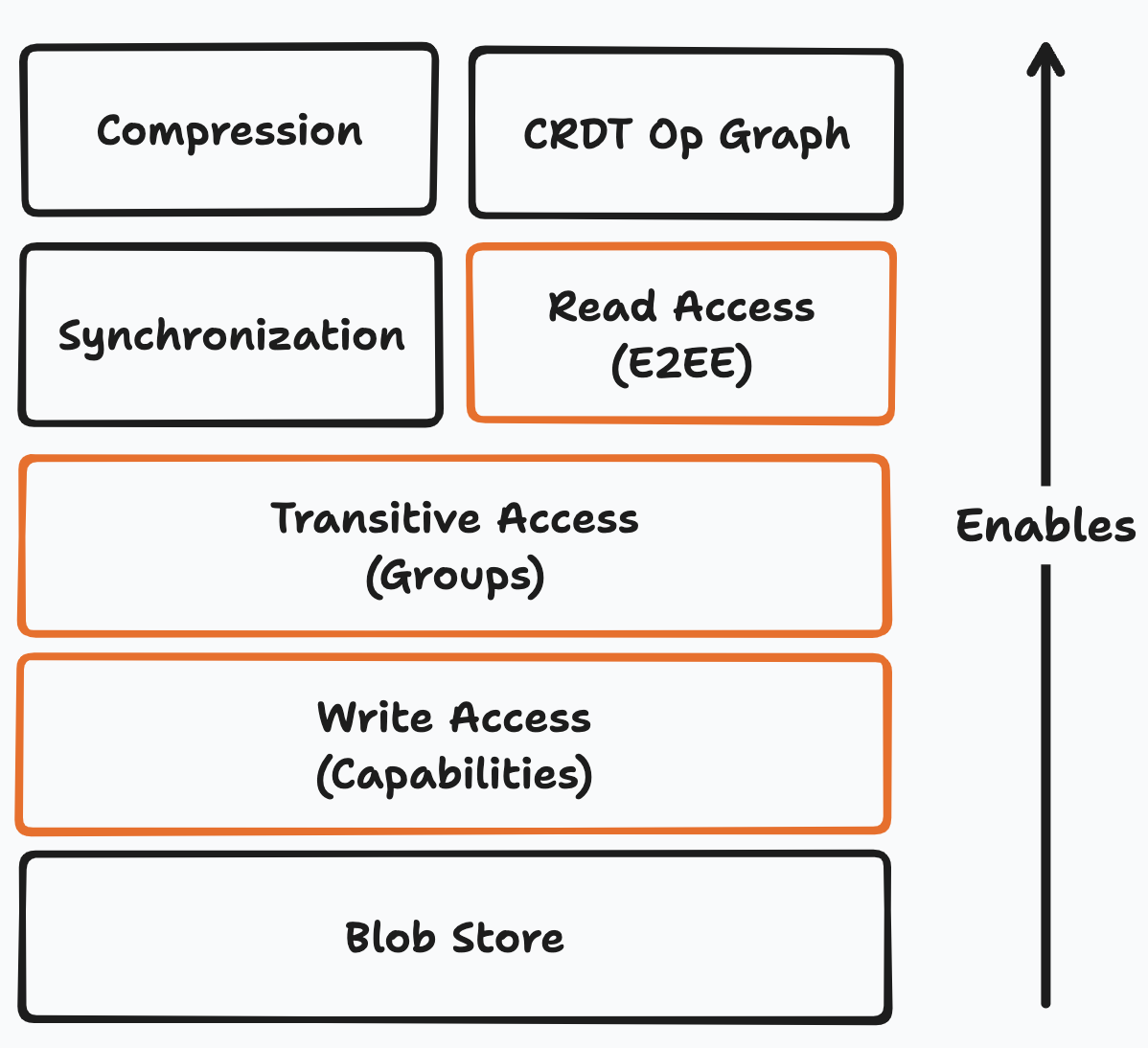
Keyhive (as currently designed) carves out three layers to handle this:
Convergent Capabilities: A new capability model appropriate for CRDTs, and sits between object- and certificate-capabilities
A Group Management CRDT: Self-certifying, concurrent group management complete with coordination-free revocation
E2EE with Causal Keys: With post-compromise security (PCS) and symmetric key management granting access to causal predessesors.
These three have a strong dependency between each other. Capabilities enable use to manage groups, and groups let us share keys for E2EE. We will go into more detail on all three in future posts, but in the meantime here is a very high level treatment:
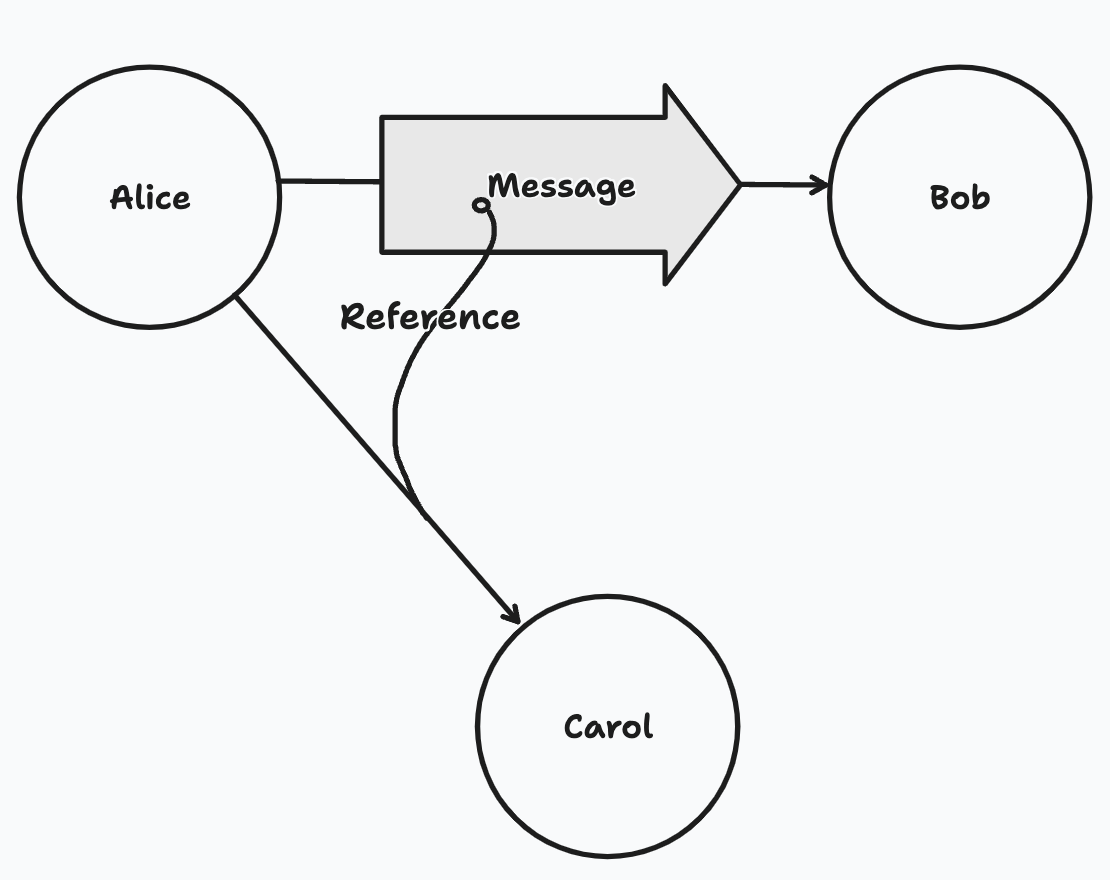
A diagram showing Alice delegating to Bob her existing access to Carol
Capabilities and delegation form the basic access control mechanism that are known to be very expressive. In short: all Automerge documents get identified by a public key, and delegate control over themselves to other public keys. This provides stateless self-certification with a cryptographic proof. Public keys in the system can represent anything: other documents, users, groups, or anything else. This is a very low-level mechanism that can be used to model high level concepts like powerboxes, roles, device groups, and more with very little code, all while remaining extensible to new patterns.
Object-capabilities (AKA “ocap”) are “fail-stop”, meaning that they intentionally stop working if there’s a network partition to preserve consistency over availability. Since local-first operates under partition (e.g. offline), parts of the classic object-capability design are not suitable. Certificate capabilities such as SPKI/SDSI, zcap-ld and UCAN are partition-tolerant, but depend on stateless certificate chains which is highly scalable but somewhat limits their flexibility. We propose a system between the two: convergent capabilities (“concap” for short) which contain CRDT state to get the benefits of both while retaining suitability for local-first applications.
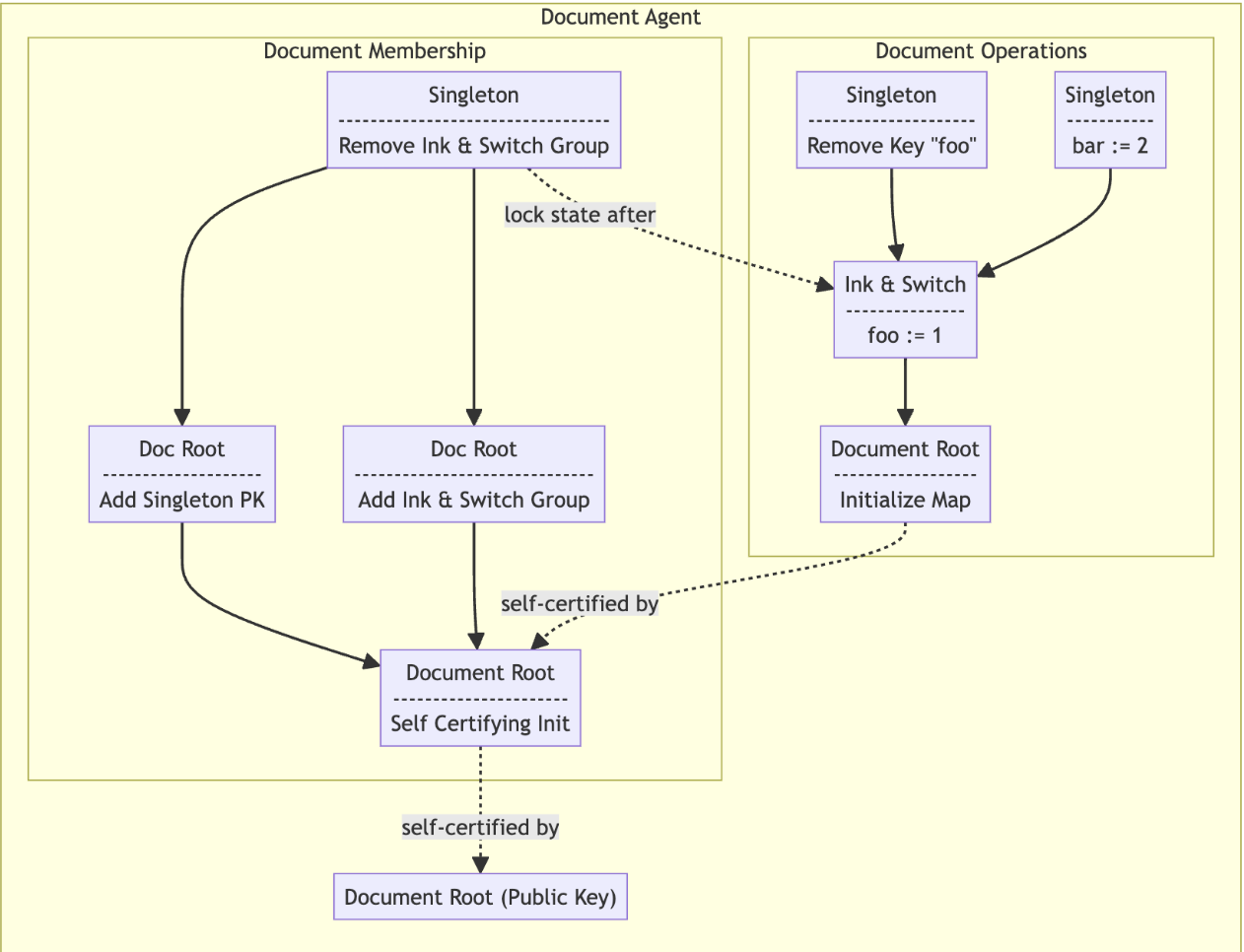
An Automerge Document Agent
A Keyhive document in isolation, with a simplified view of its stateful delegation graph.
Concurrent access control will always have some tricky situations. The big obvious ones are what to do if two admins concurrently revoke each other, or happened if operations depend on others that were revoked, and how to handle maliciously back-dated updates. There is quite a lot to discuss on this topic, so we’ll leave it for a future post.
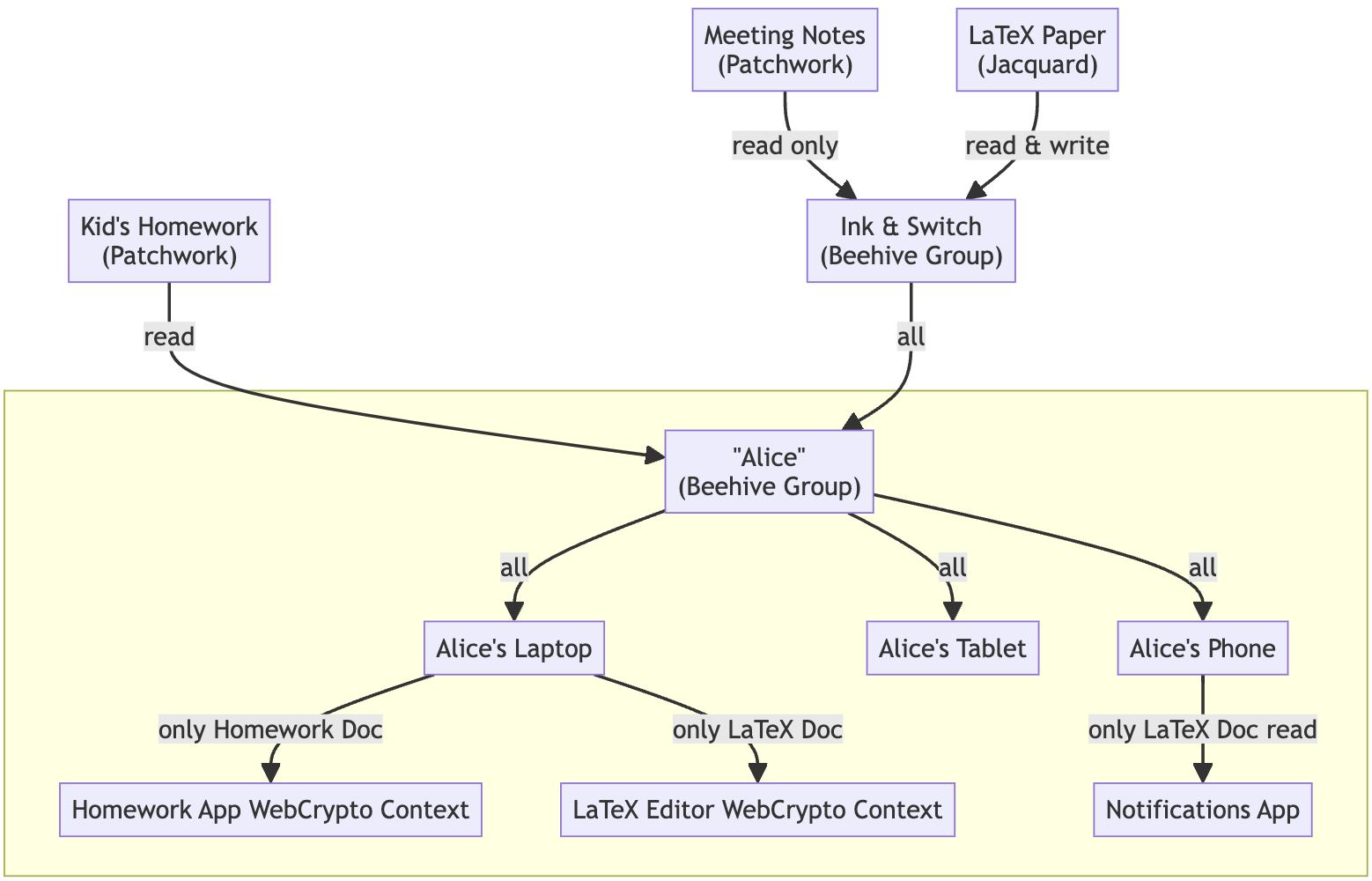
A Keyhive group showing how devices can be managed behind a proxy (‘Alice’). Documents in this scenario only need to know about Alice, not every device.
Groups are built on top of convergent capabilities. They’re “just” a thin design pattern, but help model things like user devices, teams, and more. By following the delegations between groups, we can discover which public keys have what kind of access to a certain document. This provides a handy abstraction over teams and user devices. By following the links, it both lets a writer know who has read access (i.e. who to share keys for the latest E2EE chunk with), and lets the trust-minimized sync engine know which documents the current device can request from the server.
Causal key management: a strategy for managing E2EE keys based on the causal structure of a document. Similar to a Cryptree, having the key to some encrypted chunk lets you iteratively discover the rest of the keys for that chunk’s causal history, but not its parents or siblings.
Data in Keyhive is encrypted-at-rest. Encrypting every Automerge operation separately would lead to very large documents that cannot be compressed. Instead we use the Automerge Binary Format to compress-then-encrypt ranges of changes. We expect these encryption boundaries to change over time as parts of the document become more stable, so we need a way to manage (and prune) a potentially large number of keys with changing envelope boundaries.
We achieve the above by including the keys to all of their causal predessesor chunks. This sacrifices forward secrecy (FS) — leaking old message keys in the case of a later compromised key — but retains secrecy of concurrent and future chunks. Of course “leaking” anything sounds bad. However, unlike ephemeral messaging (e.g. Signal) where not all users are nessesarily expected to have the entire chat history, CRDTs like Automerge require access to the entire causal history in order to render a view. This means that in all scenarios we need to pass around all historical keys, whether or not they’re in the same encryption envelope. We believe that this choice is appropriate for static control context on documents that require the entire history. As a nice side-effect of this choice, we also gain flexibility and simplicity.
In this design, keys behave a bit like pointers, so we can apply all of the standard data structure pointer indirection tricks to do smooth updates to encryption boundaries. This is fairly well-developed at this stage, so we will save a deeper exploration of this topic for a future post.
Pull Control
E2EE raises a new issue: there is no such thing as perfect security. All encryption algorithms are deemed secure with respect to some explicitly-defined assumptions (such as the difficulty of factoring large primes or group operations). There may be mathematical breakthroughs, edge cases discovered, or new hardware that render your choice of encryption algorithm useless. Even more worse, keys can be accidentally leaked or devices stolen. While we can revoke future write access, if someone has the data and the symmetric key, then they have the ability to read that data. The best practice is to have defense in depth: don’t make ciphertexts retrievable by anyone, but only those with “pull access” or higher. “Pull” is weaker than the more familiar “read” and “write” access effects: it’s only the ability to retrieve bytes from the network but not decrypt or modify them. This is especially helpful for trust-minimizing sync servers, since by definition they cannot have the ability to see the plaintext if we want to claim E2EE.
Access Effects
An example of delegation across the Keyhive access effect types
Trust Minimized Sync Servers
If we want to move towards an ecosystem of interchangeable relays, minimizing trust on such relays is a must. Our approach (perhaps unsurprisingly) is to end-to-end encrypt the data, removing read access from sync servers altogether. Under this regime, sync engines are “merely” a way to move random-looking bytes between clients.
There is another ongoing project at the lab focused improving data synchronization for peer-to-peer and via sync servers. We’ve realized that sync and secrecy strongly interact. Broadly speaking, sync protocols benefit from more metadata (to efficiently calculate deltas), but cryptographic protocols aim to minimize or eliminate metadata exposure. This tension extends across related systems, including merging E2EE compressed chunks, and determining if a peer has already received specific operations when a sync server cannot access them in plaintext.
Fortunately, combining these systems can sometimes result in more than the sum of their parts. For instance, convergent capabilities help facilitate the calculation of which documents are of interest to particular agent, helping the sync system know which documents to send deltas of. For these reasons, we’re treating synchronization and authorization as part of a larger, unified project, even though each will yield distinct artifacts.
What’s Next?
Cryptographic code is notoriously difficult to debug, so we decided to start with design and move to code when we had some fairly good theories on how the basics of this system should work. Now that we’re at that point, we’ve very recently begun to implement this design. We’ll report on our progress in future posts, as well as dive deeper into some of the topics we touched on in the overview here.
As we’ve seen in past lab notes, Keyhive provides access control for local-first applications. We support both server-based collaboration and peer-to-peer operation without a trusted server. And individuals might work offline for extended periods of time. In the context of Automerge, our goal is to control access to documents, collections of documents, and parts of documents.
Every document has a group of users with access to that document. That group might include other groups as members (in which case the members of those groups are also members of the document). Importantly, a document group’s membership is dynamic, with new members added and removed over time. We must be able to handle concurrent changes in a distributed context.
Of course, if we want to limit read access to just our group, we can’t safely share our document as plaintext via sync servers. We need a way to encrypt and decrypt our data that is accessible to only our document’s members. This means we need a way for our group to agree on the keys that will be used for encryption and decryption over time.
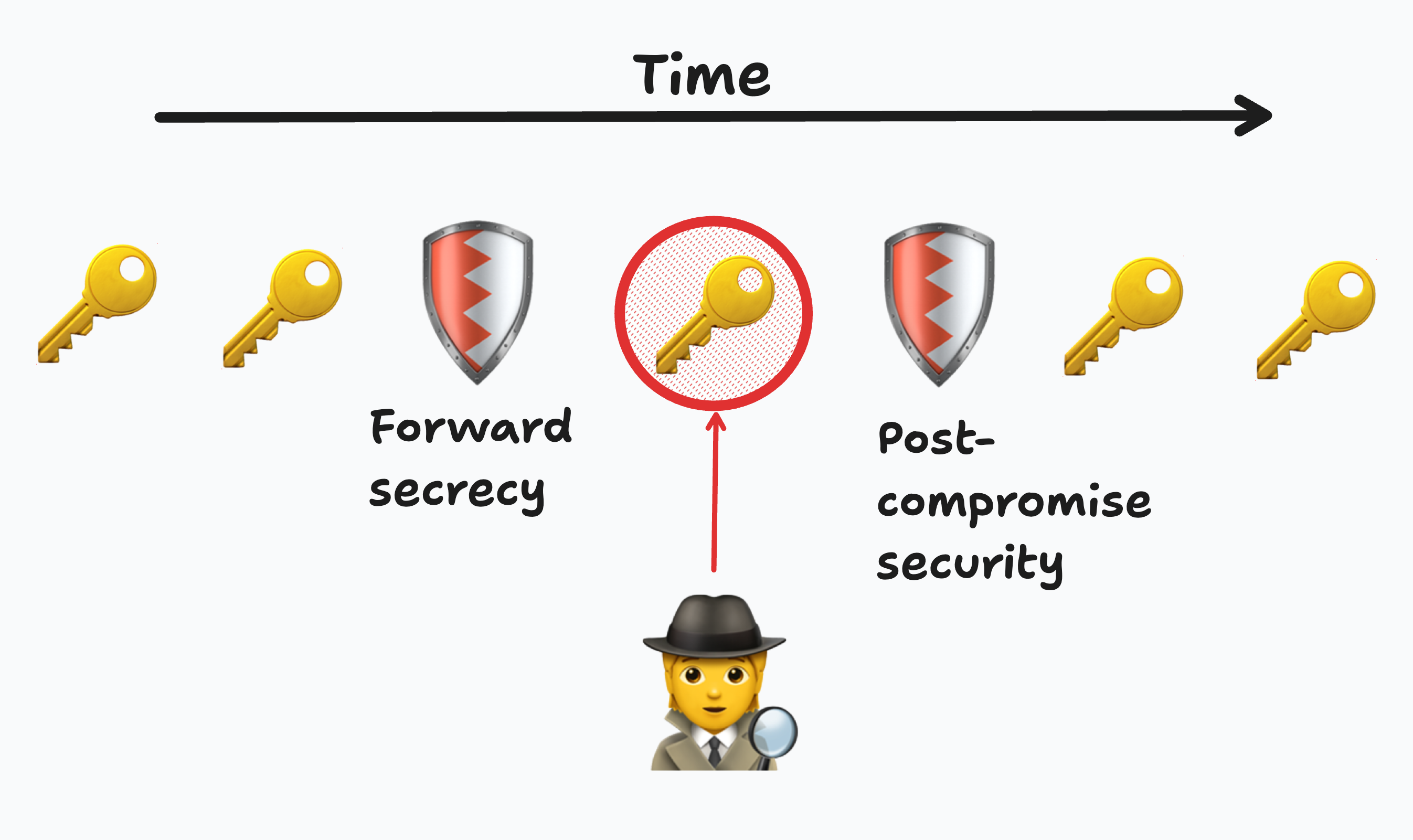
In the literature, this problem is known as Continuous Group Key Agreement (CGKA). A CGKA protocol enables a dynamic group to agree on a sequence of keys over time. CGKAs ordinarily guarantee two properties: forward secrecy (FS) and post-compromise security (PCS). Imagine a successful attacker compromises a single key. In the simplest terms, forward secrecy means that this key will not enable access to past data. And post-compromise security means it will not enable access to future data. If you can guarantee both, then you can limit the damage from a key compromise.
One way to achieve forward secrecy is through “ratcheting”. With a ratchet, honest users employ a key derivation function (KDF) to deterministically transform a key in a way that is effectively impossible to reverse. A cryptographic hash function is one way to achieve this. Ratcheting with such a one-way function prevents an attacker from discovering past keys since there is no feasible way to reverse the function. But a one-way function on its own does not prevent an attacker from discovering future keys, since you can derive all future keys from a compromised key by repeatedly applying the hash function.
Of course, we don’t want a system that once compromised is always insecure. That’s where post-compromise security comes in. The intuitive idea is that a system with post-compromise security has some mechanism to deny access after an attack. Compromised information will no longer be enough to derive future keys. One way to achieve this is to periodically rotate information required for determining future keys in a way that is not accessible to a past attacker.
In practice, ratcheting protocols mix in fresh information with each ratchet so that knowledge of a key is not by itself sufficient to derive future keys. For example, Signal’s Double Ratchet protocol includes sending a Diffie-Hellman public key with each message so that the receiver can derive a shared Diffie-Hellman secret to use as a side input to the key derivation function (KDF) that is used for ratcheting.
The current Message Layer Security (MLS) protocol for CGKA uses TreeKEM, a protocol for asynchronous, decentralized key agreement for dynamic groups1. TreeKEM uses a binary tree with group members’ public keys at the leaves and the current group secret encrypted at the root. All other inner nodes act like the root for their subtrees (and subtrees act like subgroups with their own shared, encrypted secrets). Members can be dynamically added and removed from the tree.
For post-compromise security, each member periodically rotates out its public keys on its leaf, which leads to cascading secret updates all the way to the root. Both updating and decrypting the root secret requires traversing the path from the member’s leaf to the root, performing log(n) operations (although there is a linear worst case under certain conditions).
Unfortunately, Keyhive’s requirements rule out TreeKEM as it stands. That’s because TreeKEM depends on a central server to create a total order of operations, and to pick winners among concurrent operations. Keyhive’s local-first model is peer-to-peer compatible and does not require such a central server. And for Keyhive, concurrent operations can be merged in long after they were actually performed (for example, if a member made changes while aboard a long-haul flight).
An alternative that is more aligned with our requirements is the Decentralized Continuous Group Key Agreement (DCGKA) protocol developed by Matthew Weidner and Martin Kleppmann. This protocol assumes a decentralized network that does not depend on a trusted central server. However, unlike TreeKEM, it provides linear rather than logarithmic performance. As a result, they target groups on the order of 100 members as opposed to MLS’s target of 50k members. A design goal for Keyhive is to target at least thousands of members2.
Matthew Weidner has also proposed an alternative to TreeKEM called Causal TreeKEM. Whereas TreeKEM requires a total order imposed by a central server, Causal TreeKEM only requires a causal order, which is much better suited to a decentralized network. Like TreeKEM, it has logarithmic performance (with a linear worst case) and is meant to ensure both forward secrecy and post-compromise security.
However, Causal TreeKEM depends on fancier crypto than we’d prefer in order to merge concurrent updates in any order. It requires a cryptographic operation to combine updates at a node that is both associative and commutative. One option here would be BLS, but this is far less common than the standard options and there is not currently a great library option for Rust (the language Keyhive is written in). And we have definitely ruled out rolling our own crypto (you probably should too).
For these reasons, we’ve proposed our own alternative3 for Keyhive that we call “BeeKEM”. It is closely modelled on TreeKEM with insights from Causal TreeKEM. It requires no central server and only a causal order of operations. It provides logarithmic performance (with linear worst case). And like the other TreeKEM variants, it provides forward secrecy and post-compromise secrecy4. Furthermore, it relies exclusively on standard crypto, such as Diffie Hellman key exchange and BLAKE3 hashing.
In this section, we’ll see how BeeKEM works in more detail.
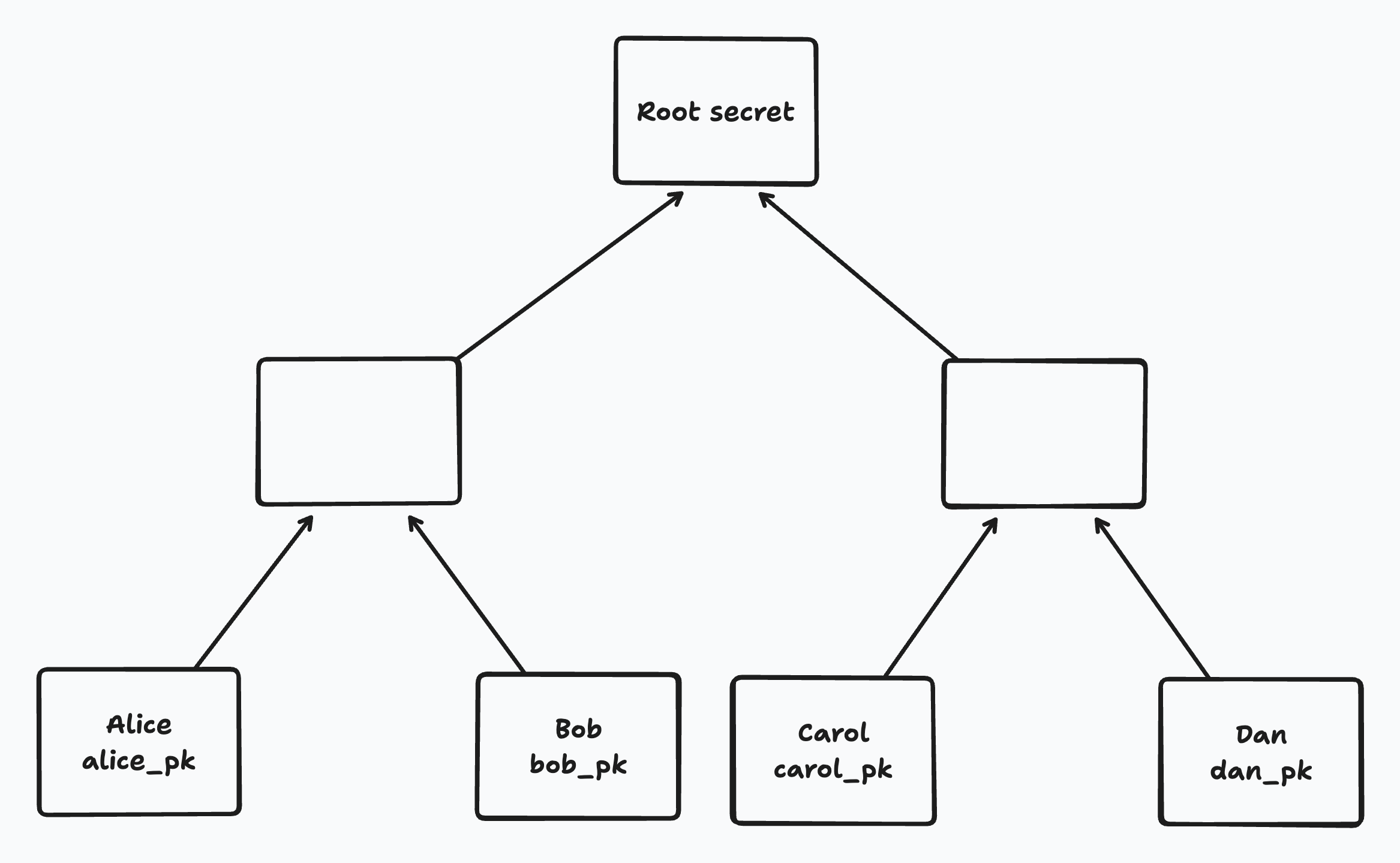
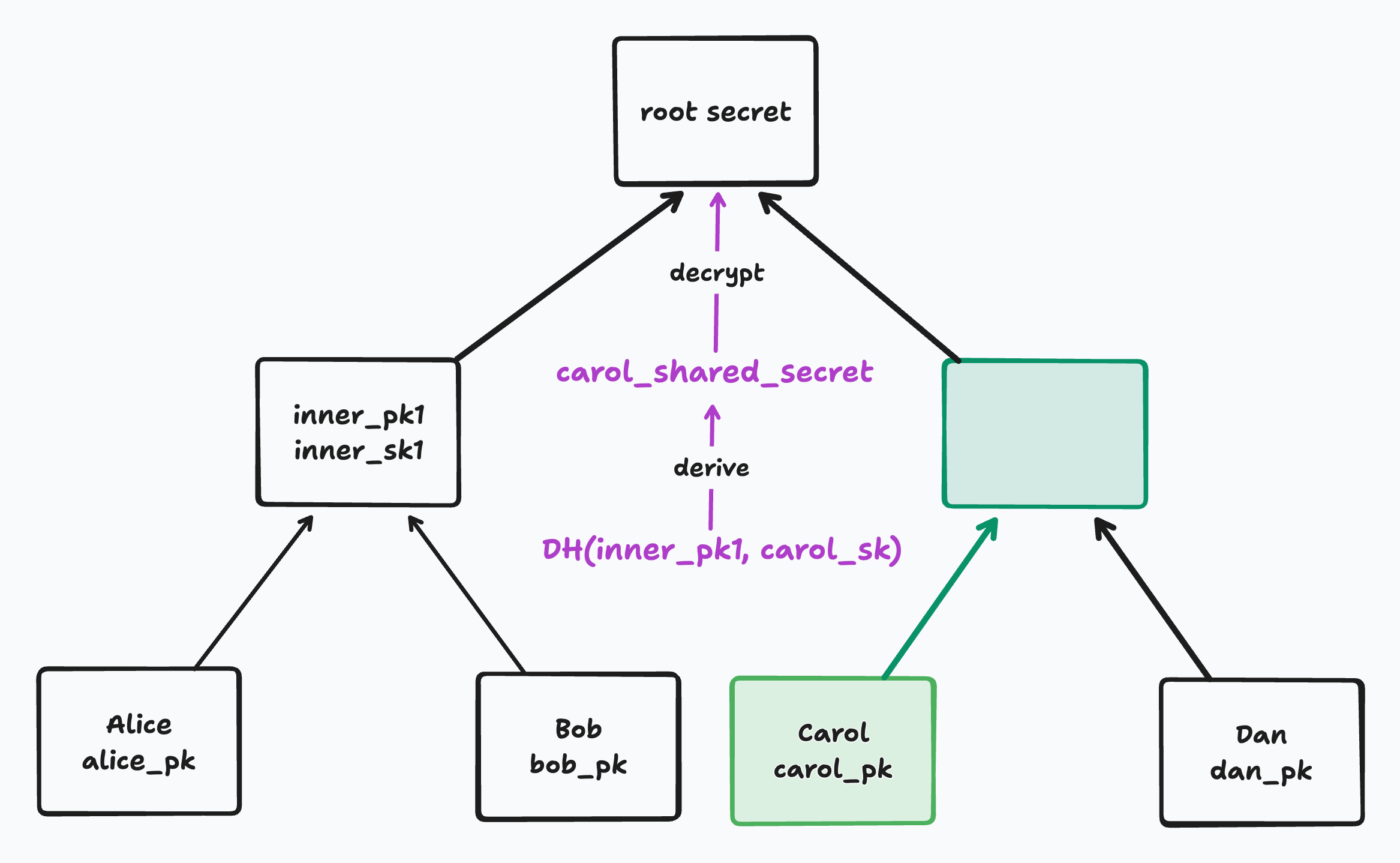
In BeeKEM (as in TreeKEM), the current group secret is stored encrypted at the root node of a binary tree. We’ll call this the “root secret”. The root secret is used for encrypting and decrypting document chunks shared with our group over the network5.
Each leaf of the tree corresponds to a member of the group and contains its ID and latest Diffie Hellman (DH) public key. A member’s ID is persistent over time but each member will periodically rotate its DH public key. When a member rotates its DH public key, that will cause the root secret to change as well. Thus, member key rotations help provide post-compromise security. From the point of view of an adversary, they introduce fresh randomness.
Each leaf has an implicit secret known only to the corresponding member (i.e. not stored in the tree). All other “inner” nodes in the tree contain a DH public key for that node and a corresponding secret key that is stored encrypted at the node.
Each node in a binary tree has a single sibling node, as illustrated in the following diagram:
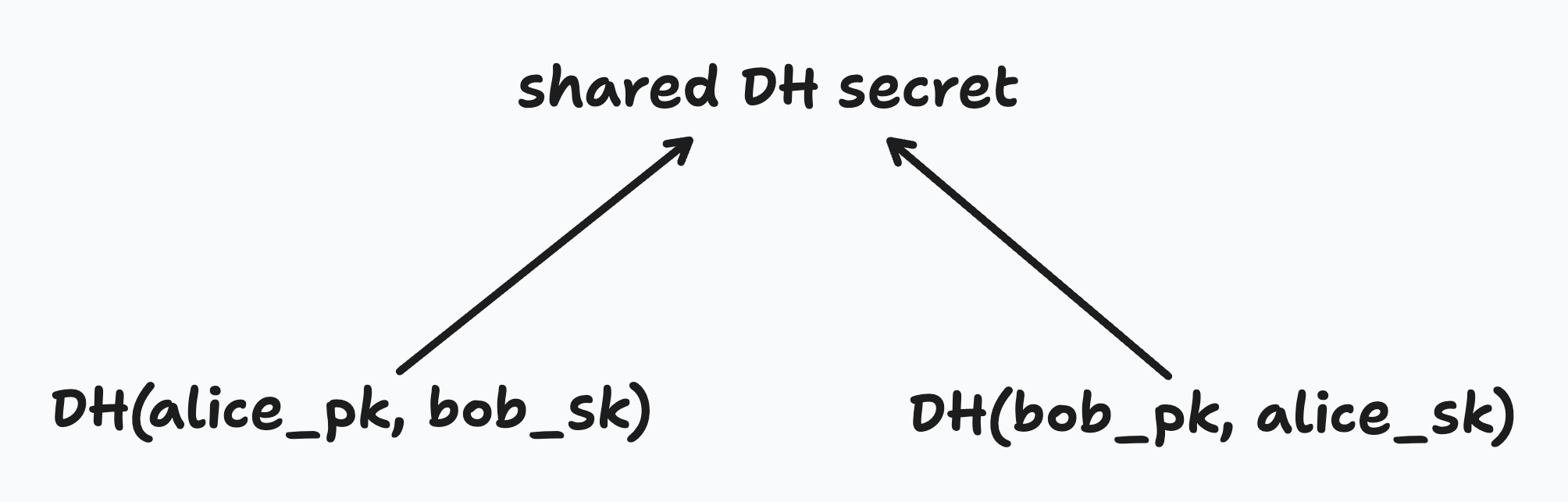
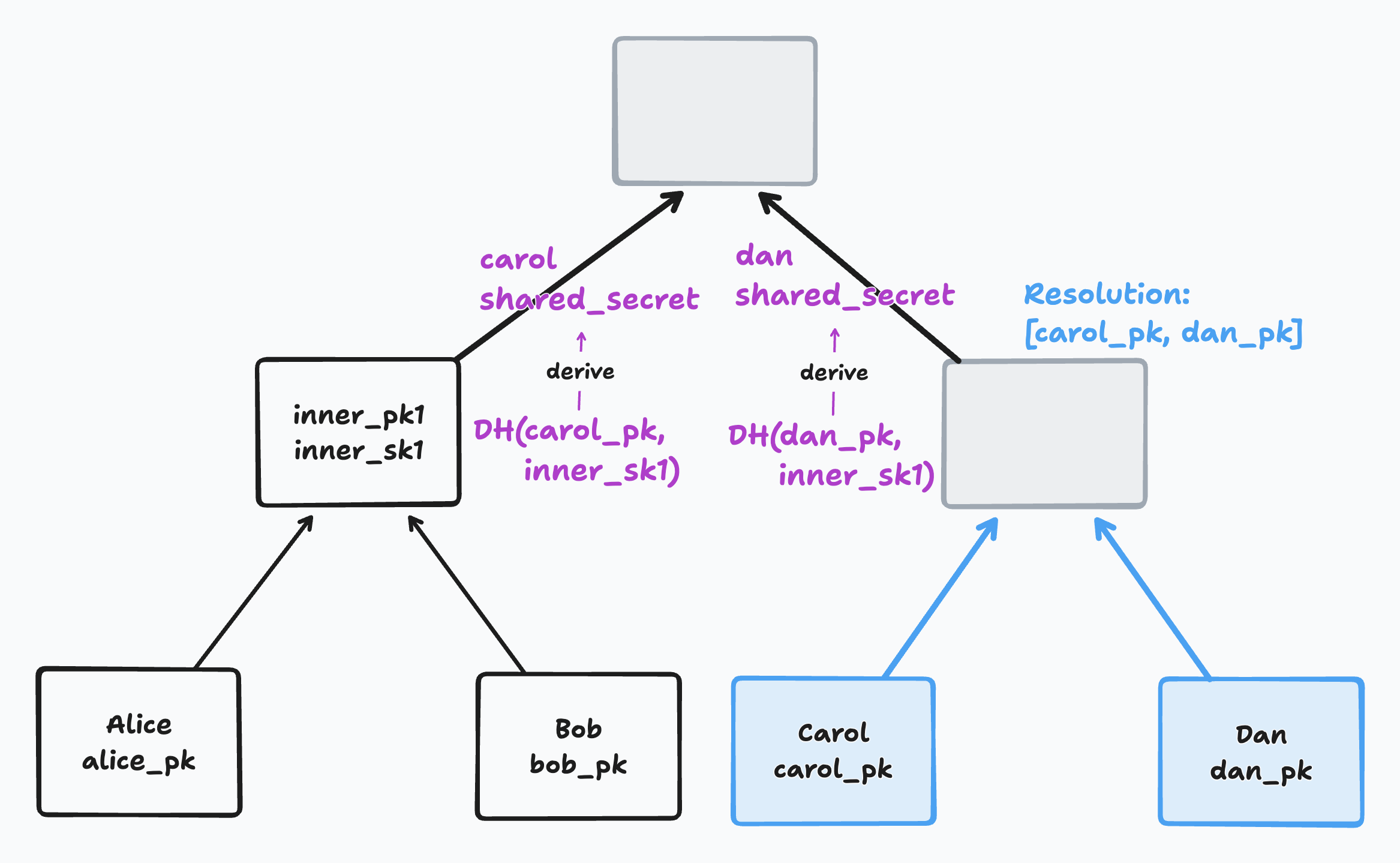
When encrypting or decrypting a new secret at a parent node, a child node performs a Diffie Hellman key exchange with its sibling. That means it will use its sibling DH public key and its own secret key to derive what we’ll call a “shared DH secret”. The shared DH secret is used to encrypt and decrypt the new secret at the parent.
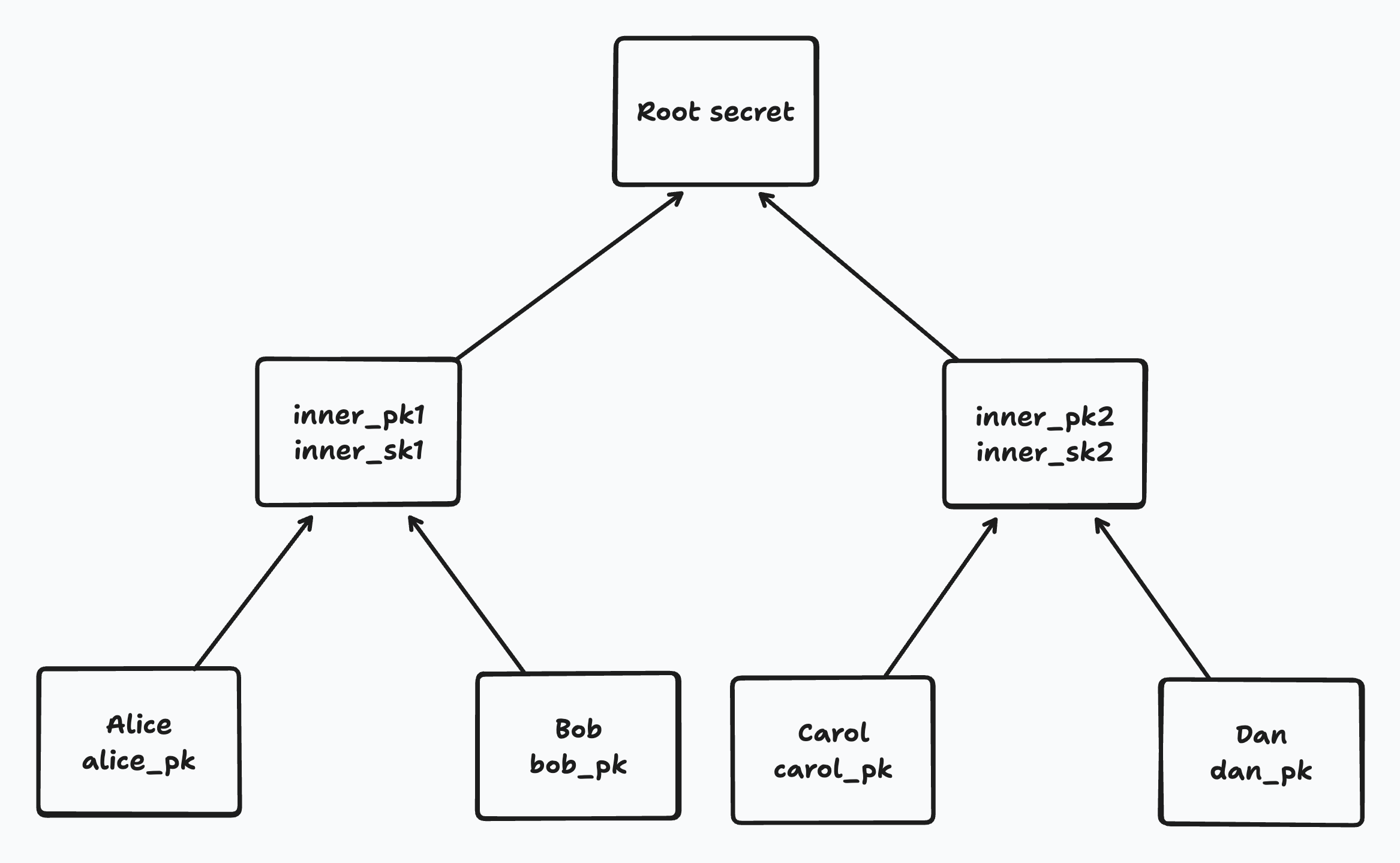
A brief (simplified) aside on how Diffie Hellman key exchange works. Imagine Alice and Bob each have their own DH public keys (alice_pk and bob_pk) and DH secrets (alice_sk and bob_sk). If Alice combines her DH public key with Bob’s secret key, she can derive a shared DH secret. If Bob combines his DH public key with Alice’s secret key, he can derive the same shared DH secret. In this way, they can agree on a shared secret just by exchanging their public keys in the open.
We use this same principle to derive a shared DH secret for any sibling pair in our tree. For example, to decrypt Alice’s parent node, Alice can use its secret alice_sk and its sibling’s public key bob_pk to derive a shared DH secret. It can then use that shared secret to decrypt the secret at the parent node.
That parent secret can in turn be used for a Diffie Hellman exchange with the parent’s sibling’s DH public key.
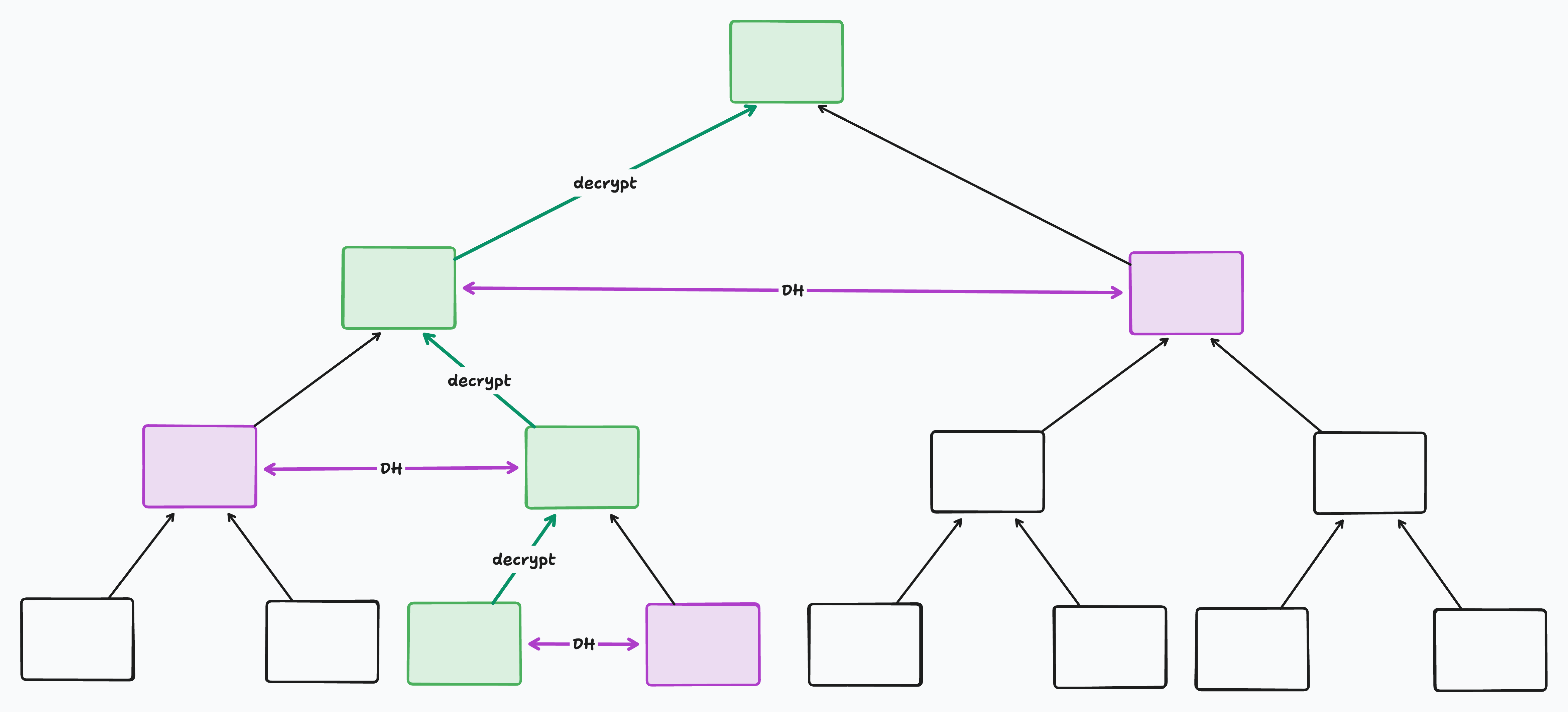
For a member to decrypt the root secret, it must start from its leaf and traverse the tree one parent at a time until it reaches the root. The sequence of nodes from leaf to root is called that leaf’s “path”. At each node in its path, it will derive a shared DH secret with its sibling to decrypt the secret at its parent. Once it’s decrypted the root secret, it’s done.
In the following diagram, the decrypting leaf’s path is marked in green. The siblings used as Diffie Hellman partners along the way are marked in purple:
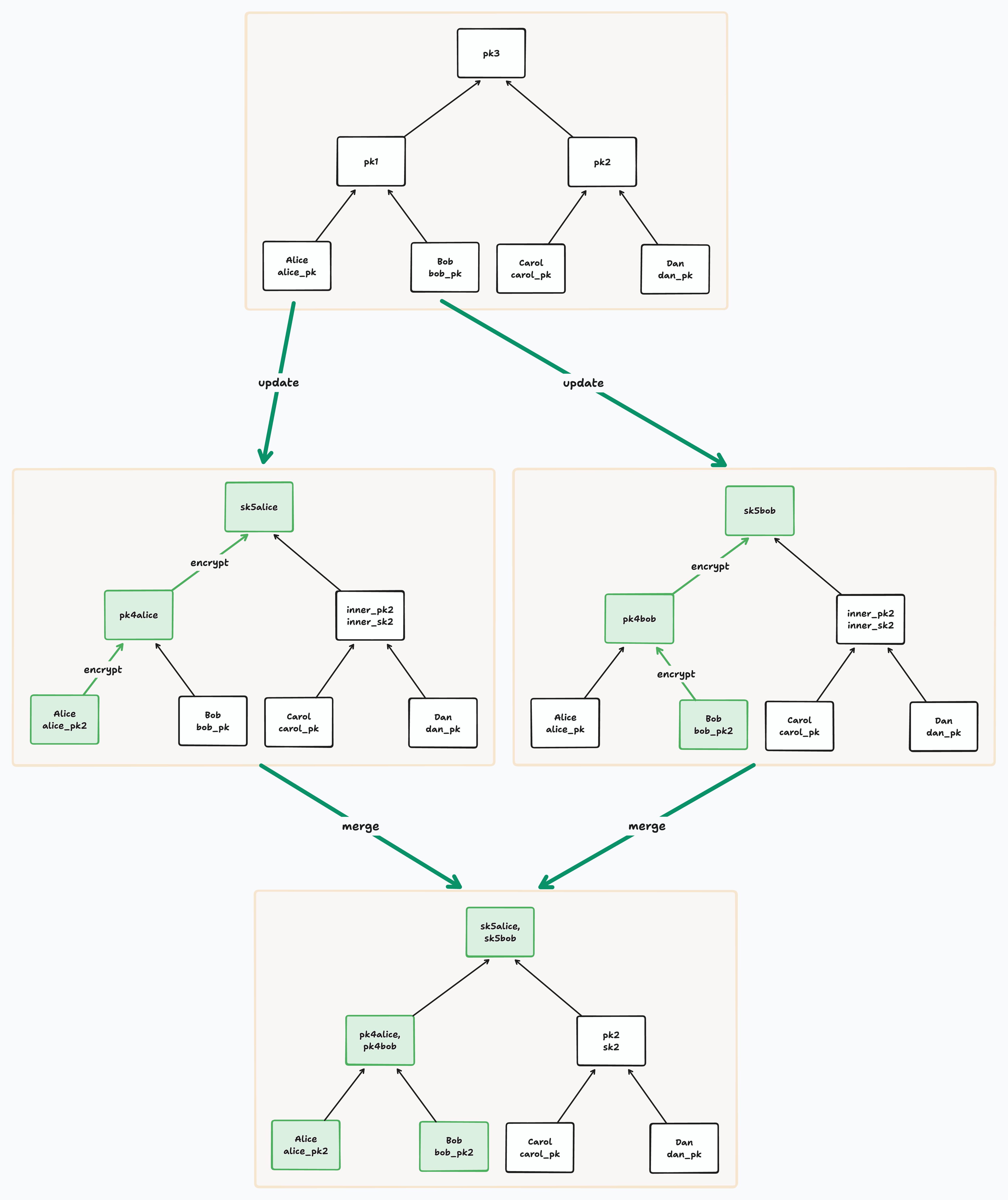
There are three mutating operations that can be performed on the tree: Update Key (i.e. key rotation), Remove Member, and Add Member. Let’s look at these in more detail.
Every member must periodically update the DH public key at its leaf in order to guarantee post-compromise security. When we update our leaf DH public key, we must then update the secrets for all the nodes on our path, eventually updating the root secret for the entire group.
Before traversing our path, we can derive a sequence of path secrets by applying BLAKE3’s key derivation function to an initial secret once for each node on the path. As we move up each parent on our path, we will encrypt the next derived secret and store it on that parent.
In order to encrypt the secret for a parent, we use Diffie Hellman key exchange as described above. We then derive a new Diffie Hellman public key from the secret for the parent, and store both that new DH public key and the corresponding encrypted secret at the parent.
Later on, when the sibling wants to decrypt that parent secret, it can do Diffie Hellman the other way, using the encrypter node’s DH public key with the sibling node’s secret to derive the same shared DH secret that was used to encrypt the parent.
In order to explain membership changes, we must introduce the concept of “blanking” a node. Blanking a node means that we remove all key and secret information from that node. If the root node is blank, then the tree does not currently hold a shared group key. Some nodes are blanked after membership change operations, and all leaves beyond the last member leaf on the right are blank.
If a tree has a blank root, then at least one member must perform an Update Key operation to restore a root secret. An update will replace all blank nodes on its update path with key information.
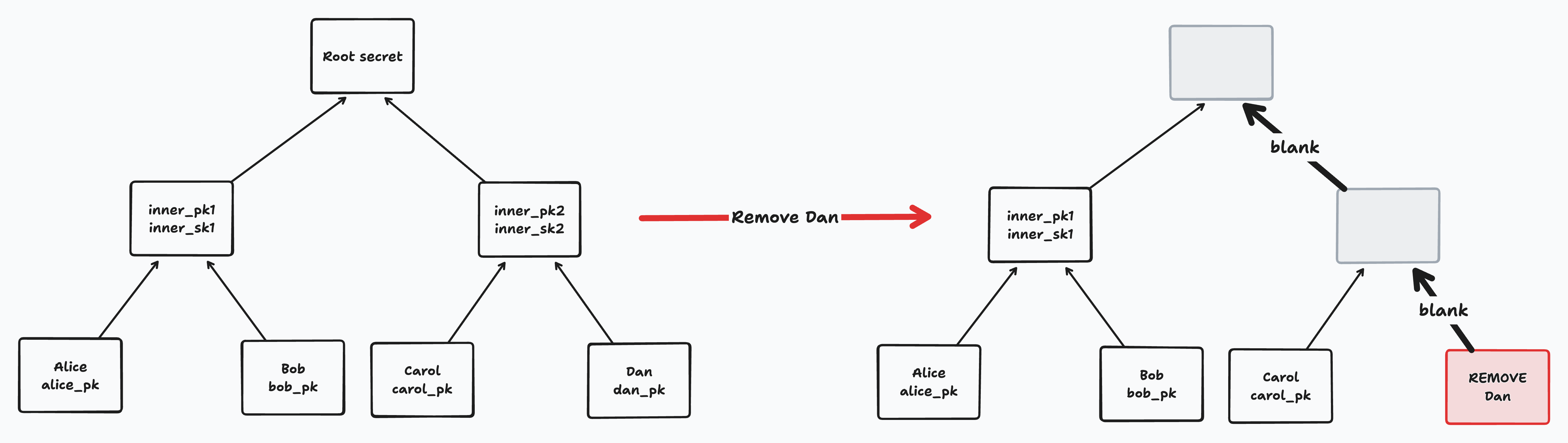
When we perform a Remove Member operation, we first blank the leaf corresponding to that member. We then blank the entire path from that leaf up to the root node.
Notice that if a removed member performs an update concurrently with its removal, we need to ensure that the update does not survive (or else the member will continue to have access to the root secret). When merging concurrent removes with other operations, BeeKEM ensures that the remove paths are blanked after all other concurrent operations are merged.
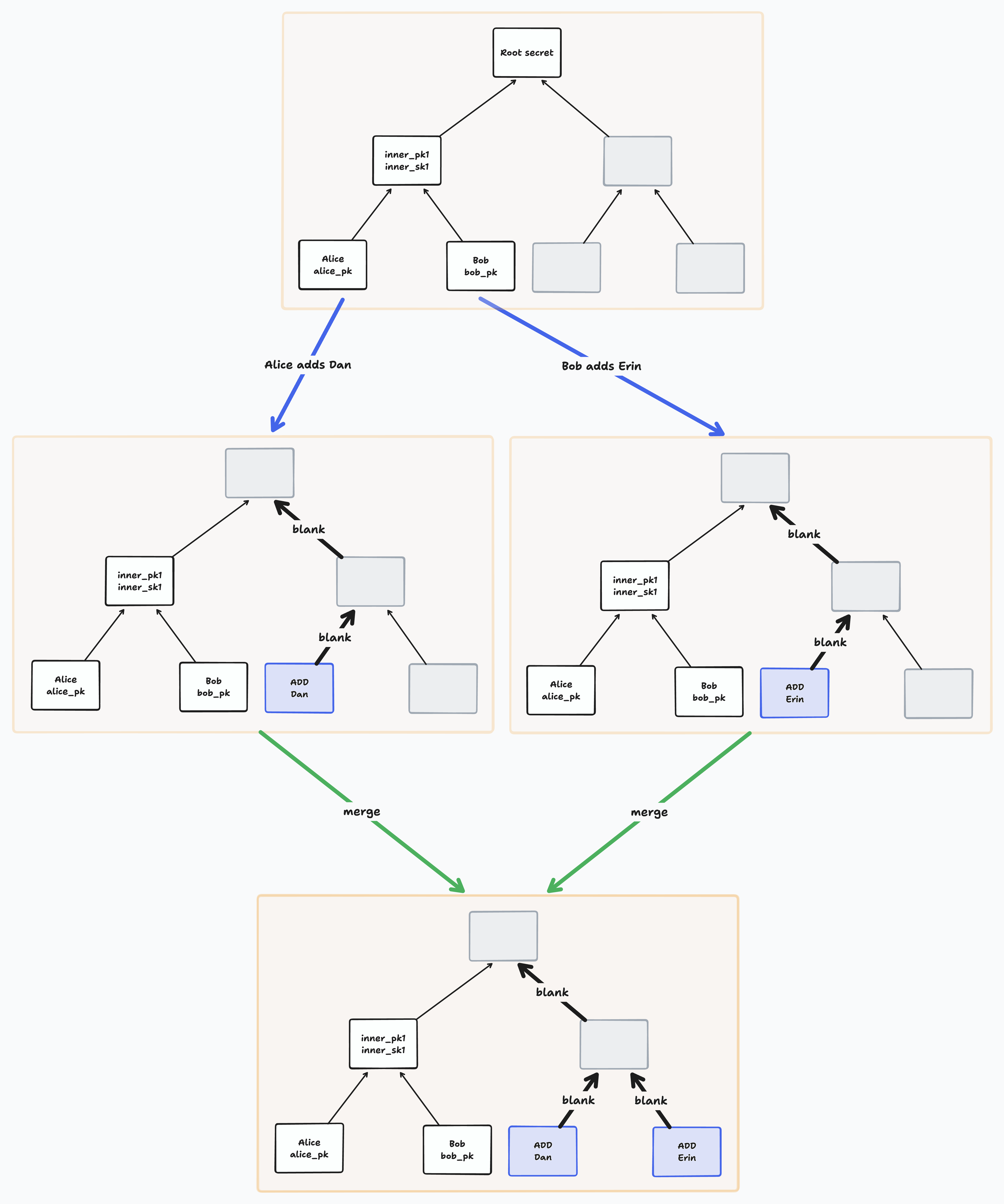
When we perform an Add Member operation, we add the new member’s ID and public key to the next blank leaf on the right. We then blank the path from that leaf to the root.
Notice that if two members add a member concurrently to the same tree, they will add them to the same leaf. BeeKEM resolves such conflicts on merge by sorting all concurrently added leaves and blanking their paths.
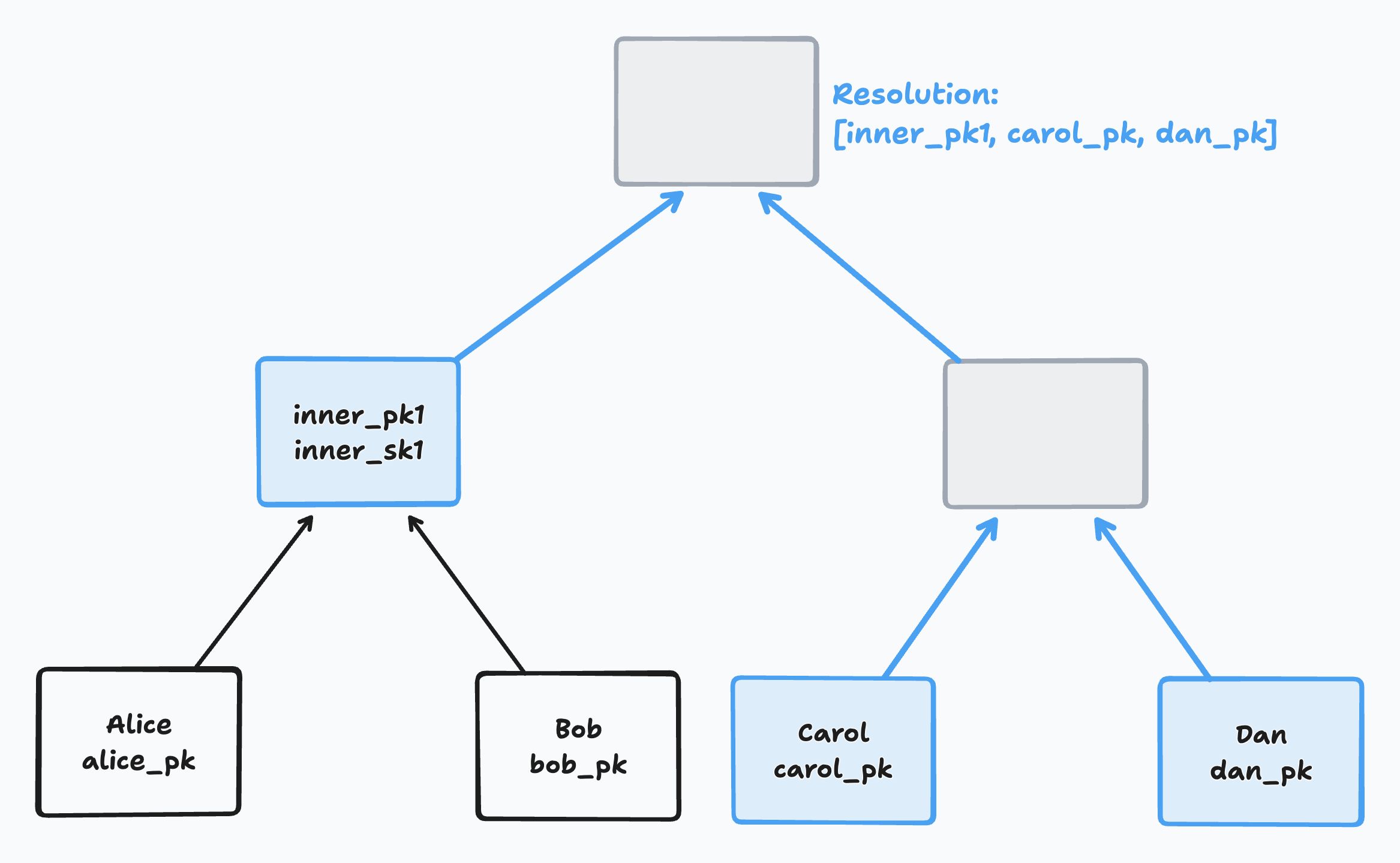
So far, we’ve assumed that every node has a sibling with key information. That’s what allowed us to use Diffie Hellman to derive a shared DH secret. But what happens when a node’s sibling is blank?
In that case, we must find the blank node’s resolution. A node’s resolution is the set of its highest non-blank descendents. Here’s an example:
If you have a blank sibling, you must do a separate encryption of the new parent secret for every member of your sibling’s resolution. For each of those members, you use its Diffie Hellman public key with your secret to derive a shared DH secret. You then encrypt the new parent secret using that shared secret and store it for that member.
This means that if the resolution of a sibling node contains 5 members, you will need to store the parent secret 5 times, each one encrypted for a separate member.
The worse case scenario is if the entire inner tree is blank. Encrypting a new path will no longer be a logarithmic operation since every leaf will be contained in the resolution of some blank node on your path. Instead, the cost will be linear in the number of leaves: you will have to perform a separate encryption for every other leaf somewhere on your path.
When decrypting a leaf with blanks on its path, you simply skip those blanks. This works because the highest blank in your path will contain its last non-blank descendent in its resolution. So when you encounter a blank on your path, you hold onto the last secret you’ve seen and start skipping. When you eventually get to a non-blank node, you’ll use that secret you’re holding onto to derive the shared DH secret you need to decrypt the non-blank parent.
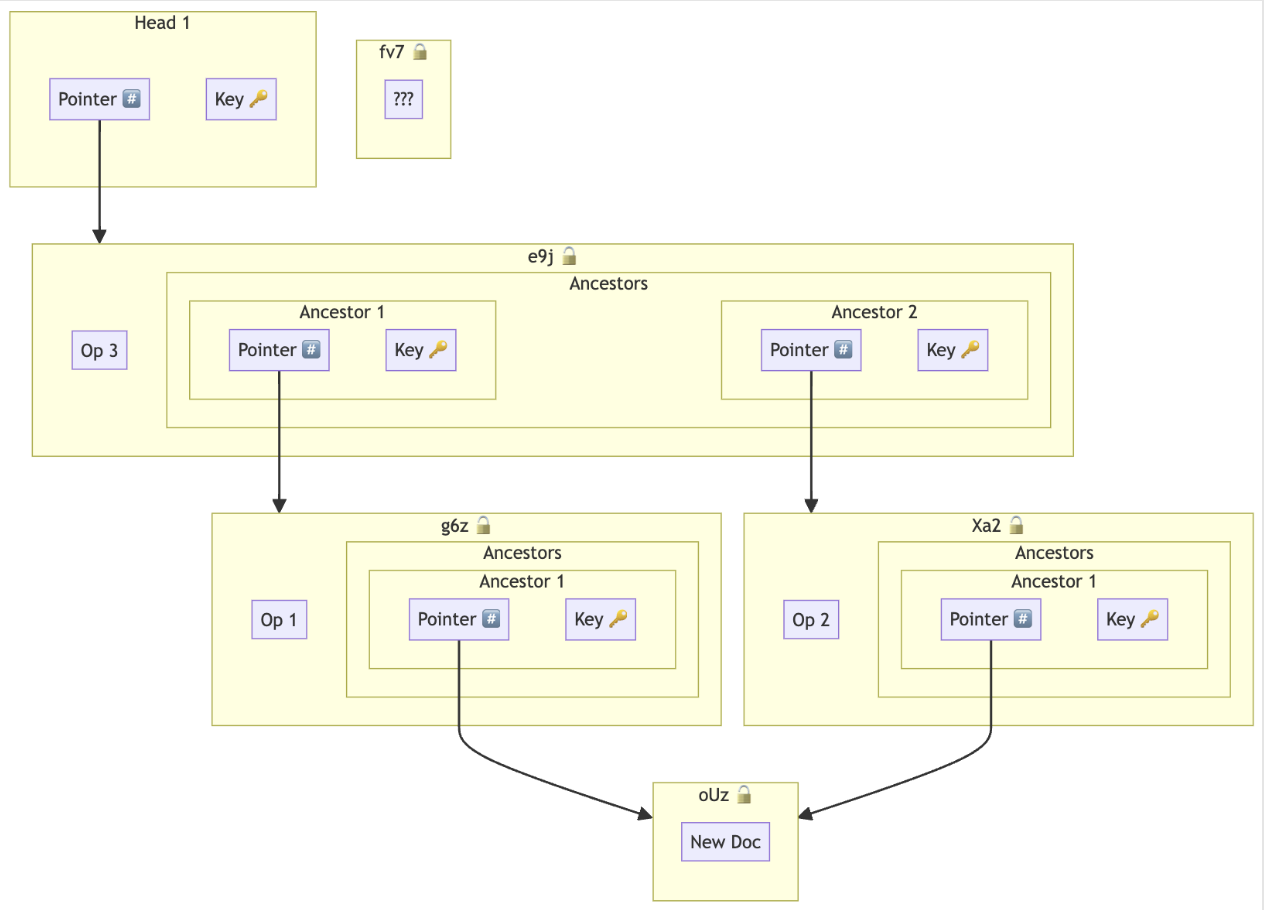
Keyhive assumes that concurrent operations can be merged in any causal order. Concurrent updates will always have some overlapping nodes in their paths (at least the root is shared by all paths). How does BeeKEM resolve these conflicts?
We must first consider our potential vulnerabilities. Imagine that an adversary has compromised a group member and their leaf secrets. They can use a compromised leaf secret to decrypt the root secret at some point in time. Recall that knowing a leaf secret means you can decrypt all of the inner node secrets along your path.
If an adversary knows the secret for a leaf, it’s possible they will continue to be able to decrypt the group secret even if that leaf is rotated during a future concurrent update. This depends on how we handle merging concurrent updates.
If we just naively pick a winner for updates to a series of overlapping nodes, then the new information added by the loser’s key rotation will no longer be necessary to decrypt the root secret. We effectively forget that information.
Notice that the winner used the outdated keys from the loser for its update (since the winner’s and loser’s updates were concurrent). That means an adversary with the loser’s outdated leaf keys will still be able to decrypt the winner’s nodes. Subsequent updates by other leaves that only intersect with the winner’s path will also fail to exclude our adversary.
In BeeKEM, when merging concurrent updates, we ensure that all updates contribute information along their entire paths. We keep conflicting information around at each node until it is overwritten by a causally subsequent operation (or blanked by a membership change).
If two leaves update the same node concurrently, then they would have each written a distinct Diffie Hellman public key and encrypted secret to that node. In this scenario, we call these “conflict keys” and store them both when merging conflicts.
Imagine a member subsequently updates the tree. If a node on its leaf’s path has a sibling with conflict keys, this means there is an unresolved merge at that sibling. An adversary could have access to both sides of the corresponding fork. So it wouldn’t be secure to use those conflict keys for Diffie Hellman. Instead, we take the resolution of the node, just as we did with blank nodes. We then separately encrypt the secret for every DH public key in the resolution, again just as we did with blank nodes.
This means that for BeeKEM we update the definition of the “resolution of a node” to mean either (1) the single DH public key at that node if there is exactly one or (2) the set of highest non-blank, non-conflict descendents of that node.
If we merged in both sides of a fork, then we know we’ve updated both corresponding leaves with their latest rotated DH public key. Since taking the resolution skips all conflict nodes, it ensures that we integrate the latest information when encrypting a parent node. That’s because any non-conflict nodes have successfully integrated all causally prior information from their descendents.
This means an adversary needs to compromise one of the latest leaf secrets to be able to decrypt an entire path to the root. Even knowing outdated leaf secrets at multiple leaves will not be enough to accomplish this. An honest user, on the other hand, will always know the latest secret for its leaf.
During a future update (key rotation), if you find a conflict key node on the path you’re updating, you can remove all conflict keys at that node and replace them with a single new public key and encrypted secret (as with normal parent encryption). That’s because your update operation is the causal successor of all the operations that placed those conflict keys. This means your tree contains the necessary information from all of those past updates, which is integrated into your update.
BeeKEM’s approach comes with two downsides. First, before conflicts are resolved by subsequent updates or blanks, we must store extra information at each conflict node. Second, conflict keys add extra encryption and decryption overhead. In the worst case, where the tree is populated with the maximum number of possible conflict keys, the space cost would be n log(n) (as opposed to the best case of 2n). The time cost in the worst case would be linear (as opposed to logarithmic), as when the tree is maximally blanked. Our current set of benchmarks reflect these time costs when we intentionally exercise our worst cases.
BeeKEM provides Keyhive with a Continuous Group Key Agreement protocol that is well-suited to distributed local-first applications that require end-to-end encryption for groups on the order of thousands of members. It exhibits logarithmic performance in the common case with linear worst case. And it provides both forward secrecy and post-compromise security.
In the future, we plan to write a paper explaining this protocol and its security and performance characteristics in more detail. But hopefully this has given you a sense for how it works.
Weidner and Kleppmann argue that secure messaging for large groups does not have a plausible threat model since it would be too easy to infiltrate them. But Keyhive is designed for shared documents. In the context of private documents shared within a company with thousands of employees, for example, we would still expect access control. It’s also worth mentioning that in Keyhive, a single user might have multiple device-specific keys (each of which will count as a member from Keyhive’s perspective). ↩︎
BeeKEM in isolation provides forward secrecy, but Keyhive as a whole does not. That’s because users require access to an entire document and Keyhive is used to encrypt that document in chunks. If you can decrypt a chunk, you will gain access to the key for decrypting the previous chunk (as described in an earlier lab note). ↩︎
More precisely, we use the root secret as one input into deriving an “application secret”. It is the application secret that is directly used for encrypting and decrypting document chunks. There can be multiple application secrets derived from one root secret, but each application secret is used to encrypt exactly one document chunk. Updating the root secret provides post-compromise security by ensuring no prior key can be used to derive application secrets associated with it. We are glossing over these details in this lab note since they strictly speaking happen outside BeeKEM, which is concerned with group agreement on the root secrets. ↩︎
The Beehive project is now officially renamed “Keyhive”!
Changing names can be a painful process, and doing so as early as possible in a project’s life is helpful. As Phil Karlton famously said, there’s exactly two hard problems in computer science: caching, naming, and off-by-one errors. Naming is important for orienting readers, searching the web, and avoiding ambiguity. We wanted to make sure that the name was finalized prior to open sourcing the code.
There is a naming philosophy that says names should be descriptive, or at least present a direct “mental hook” that implies what the signified thing does. Additional puns and whimsey help with memorability.
The previous project name “Beehive” was intended to present a sense of safety and collaboration: bees build complex-yet-sturdy structures together while working independently, and guard their hives to make a safe space on the inside. This metaphor was also inspired by earlier conversations with Christine Lemmer-Webber about metaphors to help explain capability systems (like Keyhive) to folks not familiar with formal concepts from the object-capabilities world like Vats.
At the time that we decided on “Beehive”, the team was aware of namespace conflicts in the academic distributed systems literature1. Over time it’s become clear that we also have this problem with packages in more than one language ecosystem. Since we don’t want to tie the project to Automerge exclusively, prefixing the core project with automerge-* was not appropriate.
We are retaining our apian naming for other parts of the project. BeeKEM maintains it’s pun on TreeKEM, and Beelay is the Keyhive-enabled relay.
We’re excited to announce that we’re opening the pre-alpha code for the following libraries:
beelay-core: Auth-enabled sync over end-to-end encrypted data
keyhive_core: The core signing, encryption, and delegation system
keyhive_wasm: Wasm wrapper around keyhive_core, plus TypeScript bindings
⚠️ DO NOT use this release in production applications ⚠️
We want to emphasize that this is an early preview release for those that are curious about the project. Expect there to be bugs, inconsistencies, and unstable APIs. This code has also not been through a security audit at time of writing.
The last few lab notes have focused on the cryptographic components which support a local first access control system. Those being a capability based system for managing write access to documents, and a key agreement protocol for encrypting and decrypting writes (thus implementing read control). We now have to think about how to actually transfer this data between devices.
Alongside the Keyhive project we have also been working on a new sync protocol for Automerge. The existing sync protocol works well for a single document but it is common for Automerge applications to have thousands of documents. Furthermore, the sync protocol requires that both ends are able to read the document whilst one of the objectives of Keyhive is for the server to only have access to the encrypted data.
Solving all of these problems in one go is the job of Beelay (the name is inspired by the idea of Beehive being the relay for all the bees (peers) in the Keyhive).
Beelay is an RPC protocol which is designed to be usable over any transport which can provide confidentiality (in practice, HTTPS, WebSockets, or raw TLS). The intended usage is to create a local Beelay instance and then connect it to other peers, Beelay will then authenticate with the other peers and synchronise everything which each side thinks the other has access to.
Each message is authenticated by signing it with the Ed25519 key that the local node controls. To synchronise we first synchronise the Keyhive membership graph which each end has, this allows each end to determine what documents the other end should have access to. Then we synchronise the collection of documents to figure out which documents are out of sync, before finally synchroising each individual document.
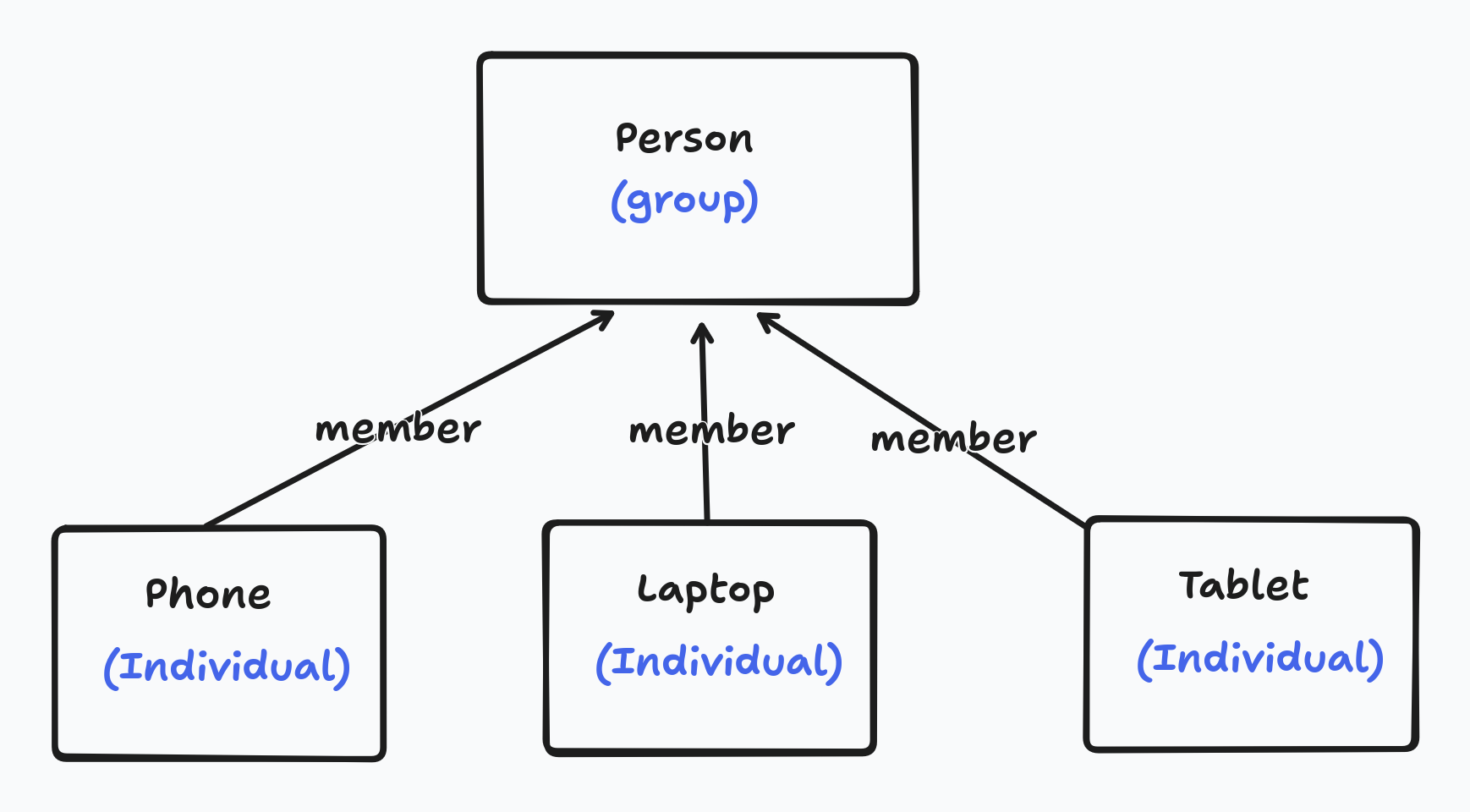
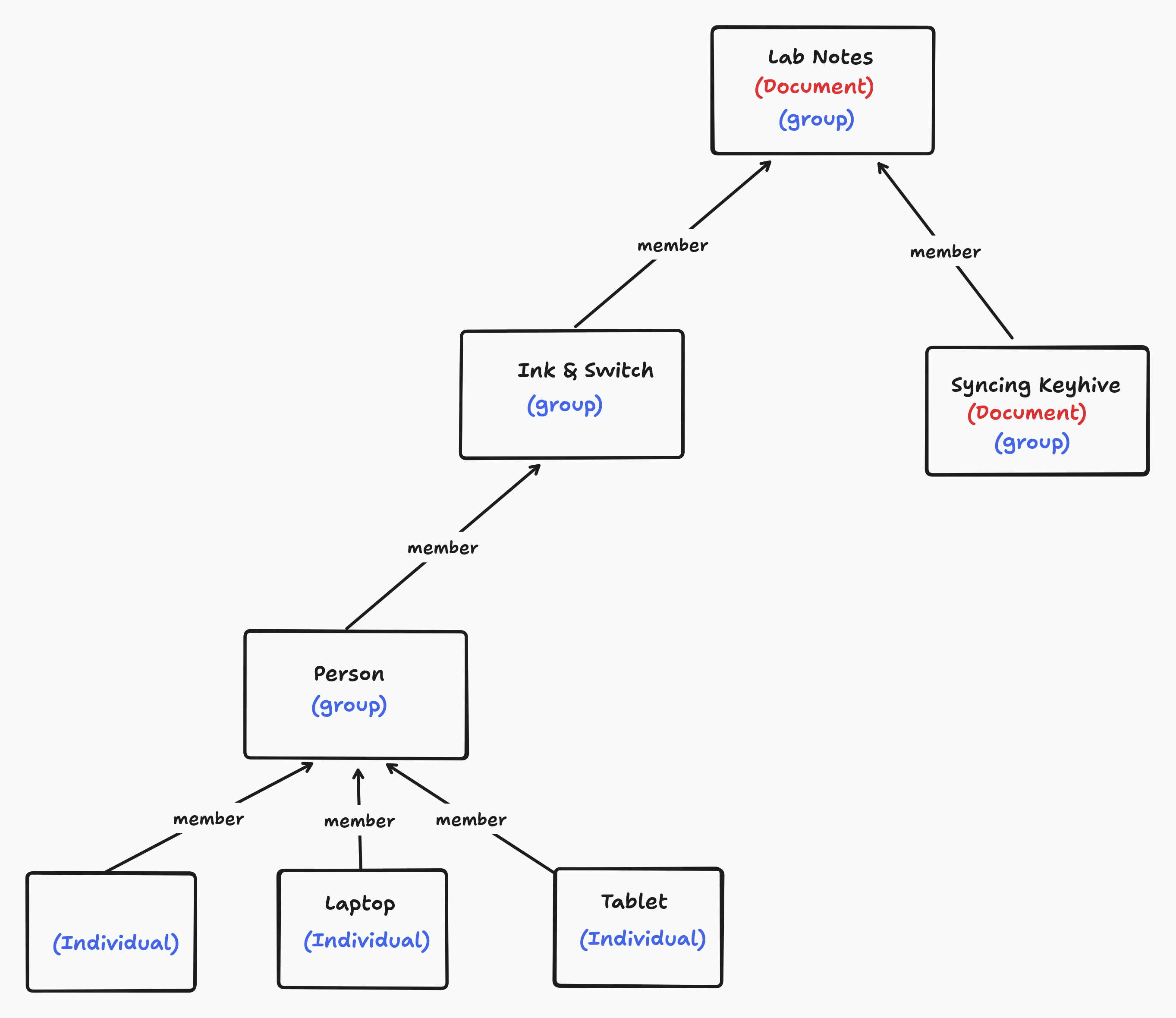
It will be useful here to review how we intend to represent devices, people, and documents in Keyhive. In Keyhive there are two important kinds of principal: “groups” and “individuals”. An individual is identified by a single Ed25519 public key - which is immutable - whilst a group is a collection of other principals (groups or individuals) and can be updated by it’s members. One way we intend to use this is to represent a person (or more specifically their authority) as a group, with each of the persons devices being an individual member of the group. Key rotation can then be handled by adding a new individual to the group and removing the old one.
Groups can contain other groups. This means that we can represent as groups, where each member of the organisation is another group representing a person (or for that matter another organisation, such as a department).
Another useful aspect of this structure is that documents can also be represented as groups. This allows documents to have members which can access the document. For example, a document representing this lab note might add the Ink & Switch group so that all (transitive) members of the Ink & Switch group can read and write to it. Documents can also add other documents which represents “folder” style relationships. The “lab notes” folder document (which is also a group, because all documents are) might contain all the lab notes and have the Ink & Switch as a member.
What this all means for the sync protocol is that any given peer is represented by an “individual”. The task of authentication is to ensure that each end knows what Ed25519 public key the other end is using so that we can relate that individual key to the Keyhive membership graph.
One solution which might seem obvious here is to rely on an authenticated TLS session. While we use TLS for confidentiality, and the browser itself authenticates the server, our application also needs to know about the server’s public key. Unfortunately, the browser doesn’t expose this information to the application context; there is no way in the browser to obtain the connection’s TLS certificate. We don’t just need to know that a connection is secure, we need to know the public key of the other end in order to use it for access control decisions and so on.
Given that each peer is represented by a public key, the simplest possible authentication scheme would be to sign each message. I.e. a message might look like this:
type Envelope = {
message: Uint8Array,
signature: Signature,
sender: PublicKey,
}
type PublicKey = Uint8Array
type Signature = Uint8Array
To authenticate a message we check that the signature is valid over the message, then we know that the other end is the individual represented by the given public key. There are two problems with this, person in the middle (PITM) attacks, and replay attacks.
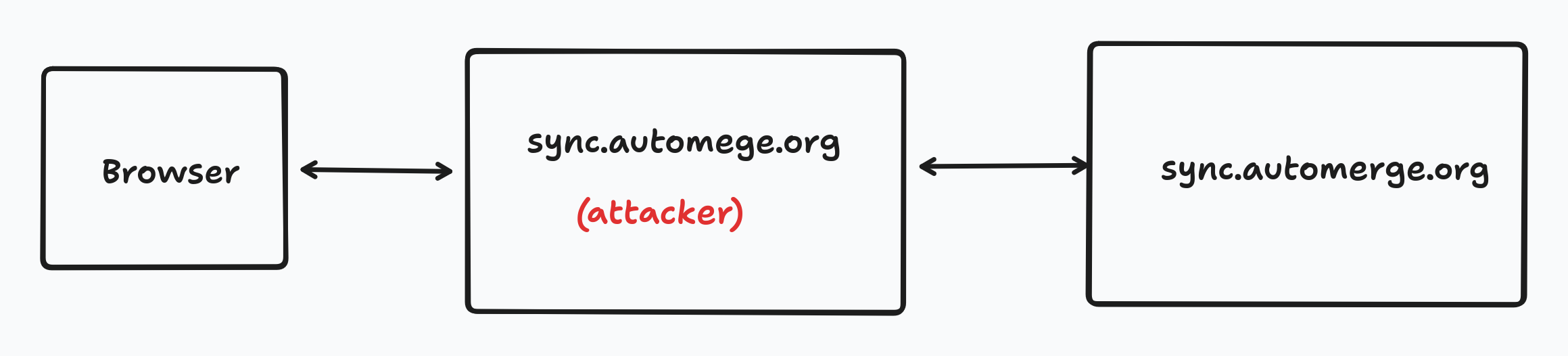
A good example of PITM attack on this protocol would be a phishing based attack. Imagine an application which allows users to input the URL of a sync server to sync from. Let’s say an attacker creates a sync server at a familiar looking URL, such as wss://sync.automege.org (note the misspelling) and convinces the user to enter this URL into their application. The attacker can now intercept all messages intended for the real sync.automerge.org server and forward them on to the sync server. This means the attacker can read all the messages and even modify messages sent back to the client.
The fundamental problem here is that the message is bound to the sender but not to the receiver. We can solve this by adding an “audience” field to the message.
type Envelope = {
message: Message,
signature: Signature,
sender: PublicKey,
}
type Message = {
payload: Uint8Array,
audience: PublicKey,
}
This doesn’t quite solve the problem above though. At this stage we only have a URL, we don’t have a public key for the server. To solve this we allow the audience field to either be a public key, or the URL we are addresssing. In this case the audience would be sync.automege.org. This means that when the PITM forwards the message to sync.automerge.org the real server can check and see that the audience doesn’t match sync.automerge.org and reject the message.
This works because the connection is being made over TLS, which binds the network transport to the hostname, ensuring that whoever is at the other end, they definitely control sync.automerge.org. Beelay is designed to work over arbitrary transports though, in other network setups such as P2P transports you will need to obtain the public key of the receiver out of band.
In a replay attack an attacker is somehow able to intercept messages and store them, and then later replay them to the server. To mitigate this we add a timestamp to the message and then reject messages which are older than some validity window that accounts for latency plus a clock skew grace period — e.g. 5 minutes.
The main issue with this scheme is that the clocks of two peers might be out of sync by arbitrary amounts of time. Soft locking the sync system due to clock sync issues is not acceptable. To solve this, when a peer rejects a message due to an old timestamp, the rejecting peer sends their current timestamp along with the rejection message. This allows the sending peer to determine the drift between their local clock and the remote clock and adjust the timestamps on the messages they send, and account for it during this session.
To authenticate a message we check that the signature is valid, that the audience is either our public key or the hash of our hostname (or some other string which is bound to the recipient in some way) and that the timestamp is new enough.
Once we are authenticated, we need to determine what each side thinks the other should have access to. This means that we need to sync the Keyhive “membership graph”. This is the graph of groups and individuals which represent devices, people, organisations, and documents.
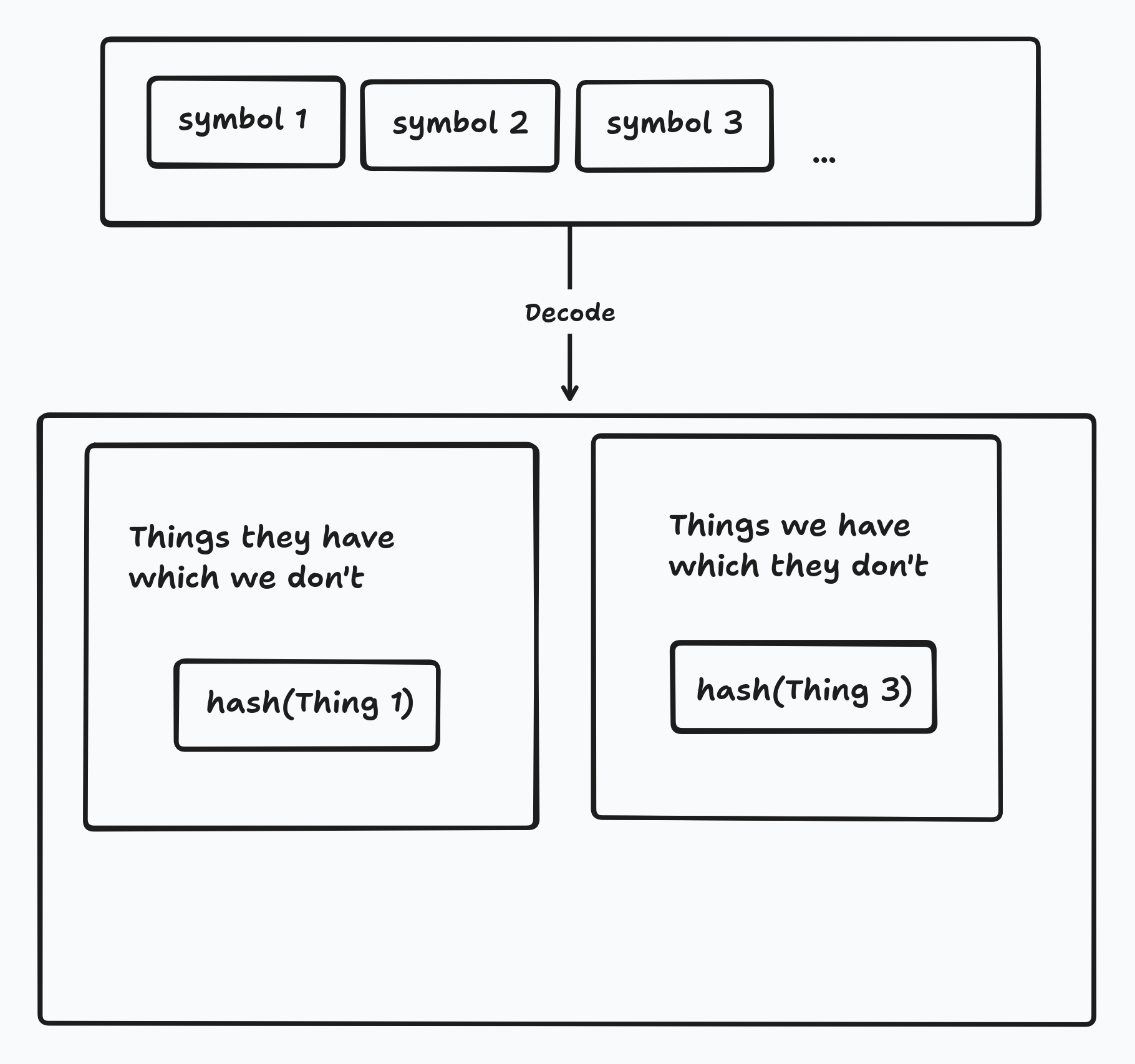
The membership graph is a directed graph of “operations” where each operation either creates a new node, delegates access to some other node, or revokes access. Unlike Automerge documents (which are also graphs) the membership operation graph is very shallow and wide, and the linked groups and documents can have cycles. There are many approaches to this problem, but it becomes much simpler if we frame it as set reconciliation, where each side has an unstructured set of operations and needs to figure out what operations the other side has that it needs (i.e. the delta between the two sets). We will encounter a very similar problem later, when we sync the collection of documents. In both cases we use a construction called Rateless Invertible Bloom Lookup Tables (RIBLT) to solve this problem.
RIBLT is described in detail in this paper, what I will describe here are the important properties that the scheme gives us.
RIBLT is a set reconciliation protocol, which means there are two peers who have some possibly overlapping set of things which they want to have the same view of. I.e. after the protocol completes each side should have the union of the things each started with.
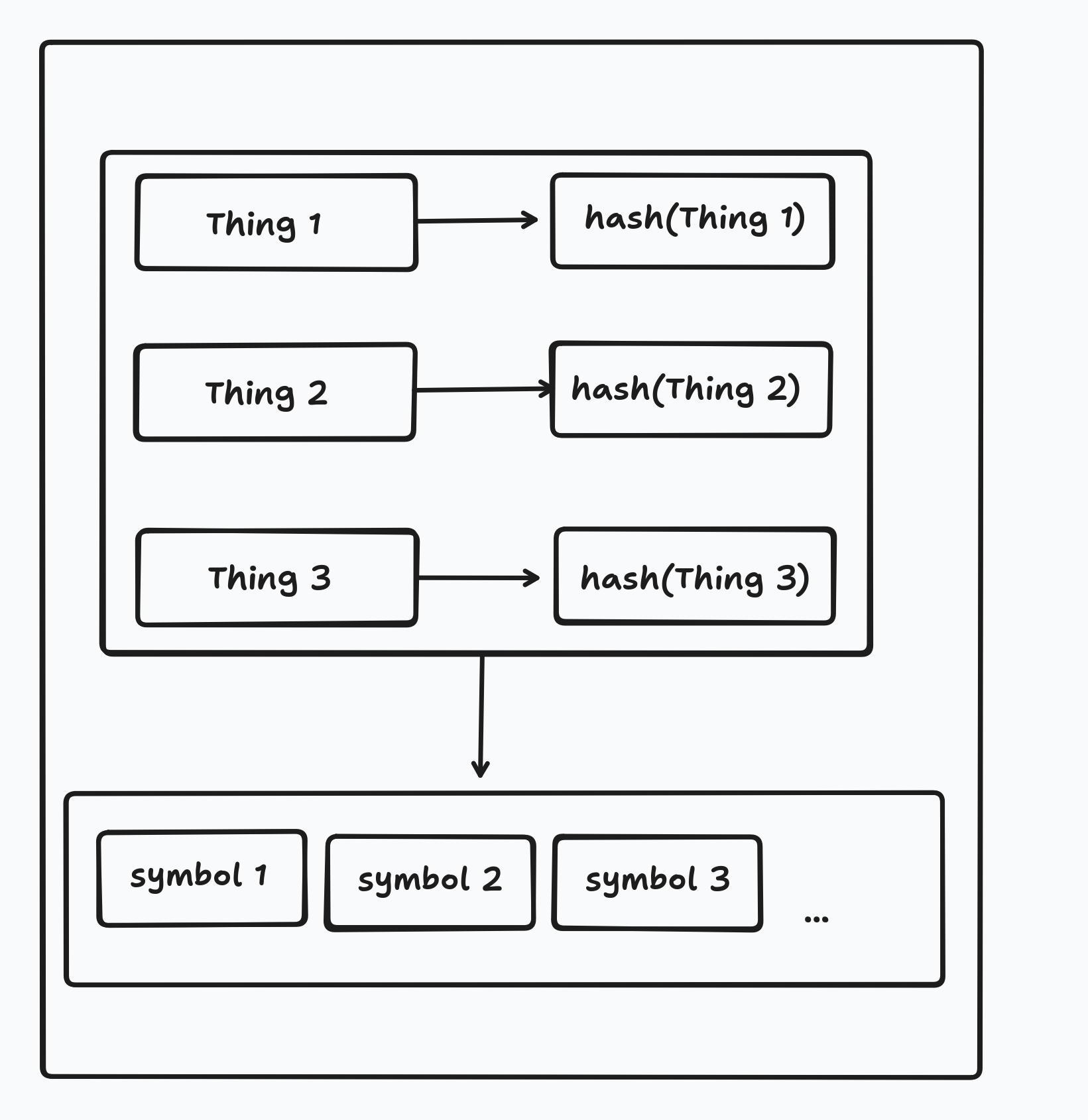
RIBLT solves this problem by having each side encode it’s set of things into a set of hashes and then generate a set of special “symbols” which one side sends to the other.
These symbols are structured in such a way that once the receiver has received enough of them they will be able to decode the symbols into the set difference.
The details are a bit fiddly but the really important part is that the number of symbols which must be sent is proportaional to the set difference between the two peers. Specifically, the number of symbols sent ranges from 1.7x (for small sets) down to 1.35x (for large sets) the set difference.
For example, If we have one billion items each, but only five differing items, we can reconcile in 5 * ~1.5 = 7.5 symbols. The symbols themselves are (in our case) 32 bytes long, so we can reconcile a billion items in 240 bytes.
The other important part is that the result of decoding is the set of hashes - not the things themselves. In fact, we can use any fixed length array which uniquely represents the thing.
So, we use RIBLT sync to synchronise the membership graph. The process is mostly driven by the client (in the peer to peer case we arbitrarily choose that the peer who initiated the connection is the client).
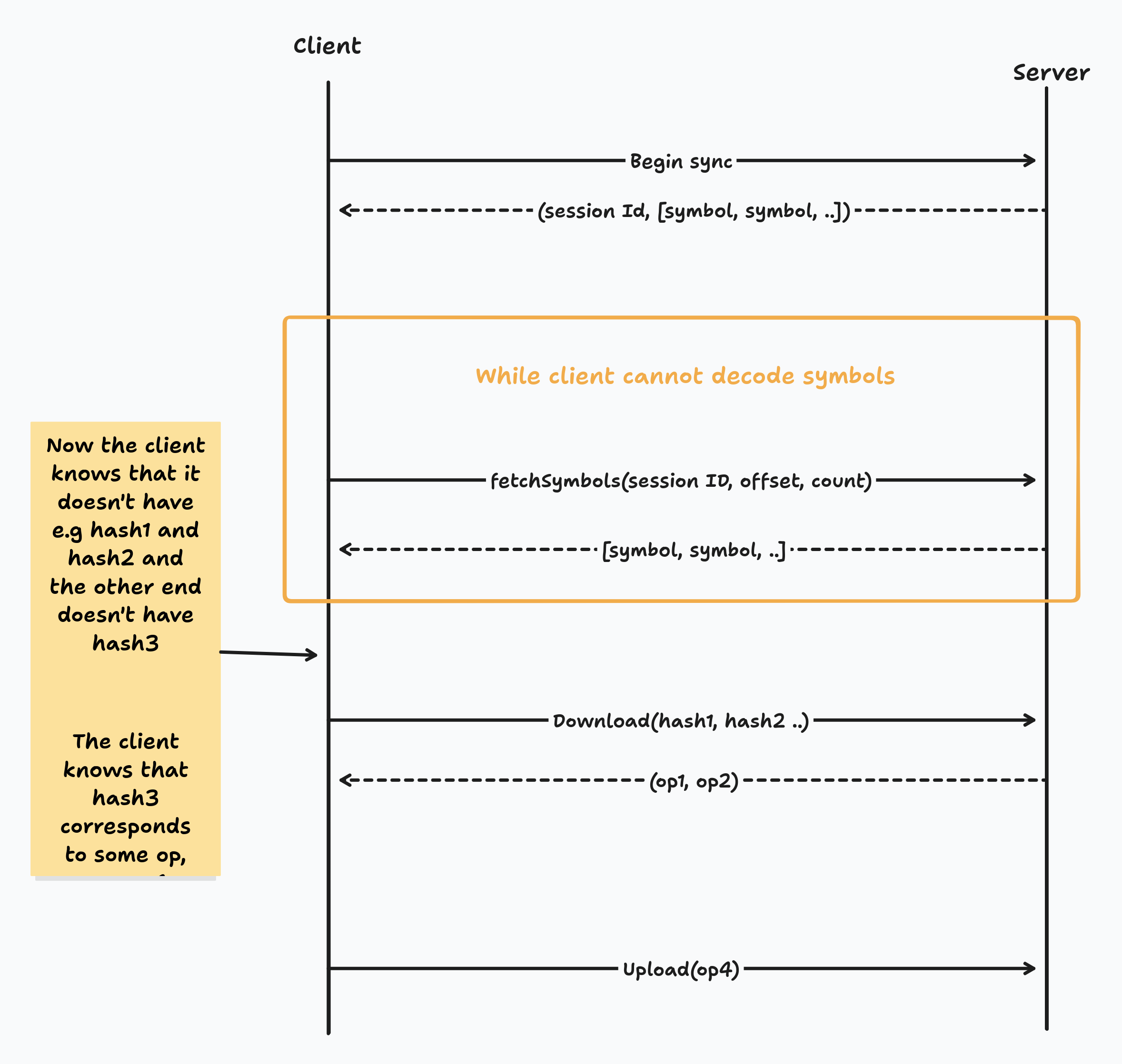
First, the client sends a request to the server to begin membership sync. The server stores a pointer to the current set of ops which it thinks the other end needs and then responds with a session ID to identify this sync session, and the first 10 symbols of the RIBLT sync.
The client now receives the first 10 symbols and attempts to decode them. If they are able to decode then they are done and they know the set difference, otherwise, they send a request for the next 10 symbols, using the session ID to specify which state they are syncing with.
Eventually the client knows the set difference in terms of hashes of operations which only the server has, and operations which only the client has. Finally, the client requests the missing operations by sending their hash, and uploads the symbols which they believe the server is missing.
At this point each end has determine what documents it thinks the other should have acces to. The next step is to determine which documents are out of sync. To achieve this we use RIBLT sync again, this time instead of the set we are synchronising being the set of membership operations it is the set of (document ID, state) pairs, where state here is a hash of the document state.
There are two components to the document state which we care about for the purposes of synchronisation. One is the heads of the Automerge document - the document content is encrypted but we keep the hashes of the Automerge commit graph outside of the encryption envelope, so the sync server knows the heads.
The other piece of state are the BeeKEM operations for the document. Recall that BeeKEM is a continuous group key agreement (CGKA) protocol which allows peers to concurrently decide on what keys to encrypt content to. We need to have the latest CGKA ops in order to be able to decrypt the document content.
How do we form our RIBLT symbols then? One way would be to make each symbol hash(document ID, document heads, cgka ops). Then, once we’ve performed RIBLT sync we make another network call to convert each symbol into the document ID which is out of sync. However, we can do a little better than this. Recall that the RIBLT symbol is just any fixed length byte array, and document IDs are a 32 byte array. This means that instead of a hash for the symbol, we use (document ID, hash(heads, cgka ops). This means that once we have decoded the symbol we already know what the document ID is for the symbol in question without doing any more round trips.
The process for actually running this sync then is similar to the membership sync. Using the session ID from the membership sync the client fetches new document symbols from the server until it is able to decode the first symbol it received, at which point it knows which symbols are out of sync.
By this point we have a list of document IDs which are out of sync. We now have to sync the CGKA ops and encrypted commit graph for each document. For the CGKA sync we can use our old friend RIBLT sync to sync the set of CGKA ops, but for the document content we need to do something a bit different because we want to be able to take advantage of the bandwidth gains we get from compacting Automerge documents.
The set we are synchronizing here is the set of CGKA ops for the document. We use the hash of each op to create our RIBLT symbols. As with other RIBLT syncs, the client requests symbols from the server until it is able to decode it’s first symbols at which point it knows what ops to upload and what ops to request.
Syncing the document content is more complicated. Initially it might seem that we could just use RIBLT sync again where the symbols to sync are the commit hashes of the commits in the Automerge commit graph. This would certainly work, however, it would use a lot of bandwidth. Automerge commits are frequently made for each keystroke, adding a 32 byte hash for each keystroke would be very expensive.
This is a specific instance of a general problem which is that naive encodings of the Automerge commit graph contain enormous amounts of metadata overhead. We have a compact binary encoding which reduces this overhead to around 10% over the underlying data. What we need is a way to use this data in the sync protocol.
In the current sync protocol this is not a problem, the sync server has the plaintext in memory and so it can compact the document on the fly when a new peer comes online. For Beelay this isn’t an option because the server only has the ciphertext. What to do?
We have come up with a simple protocol for this which we call “sedimentree”. The idea is that every so often we compress ranges of the commit graph into chunks and we do this recursively, so that every so often smaller chunks get compressed into larger chunks. We do this in such a way that older (i.e. closer to the root of the commit graph) end up in larger and larger chunks as time goes on. This forms a tree structure, with older chunks being closer to the root of the tree - hence sedimentree, with chunks being like layers of sedimentree rock.
Choosing the boundaries of the chunks is a little fiddly because we need to do it in such a way that peers with different sets of changes still agree on what should go into each chunk. We do this by using the number of trailing zeros in the hash of a commit as the boundary. There are more details on this here.
The end result of this structure is that we can sync the document in two steps:
Download a “summary” of the sedimentree, which contains just the boundaries of the chunks.
Download the chunks we don’t have, and upload the ones the other end doesn’t have
Run RIBLT set reconciliation on the membership ops
Download ops we are missing
Upload ops the remote is missing
Sync collection state
Run RIBLT set reconciliation on the set of document states
Sync out of sync documents, for each document which is out of date
Run RIBLT sync on the CGKA ops
Download CGKA ops we are missing
UPload CGKA ops the remote is missing
Run sedimentree sync on the document content
One thing which may be concerning here is the number of round trips. We should especially worry about this in the common case where only one document has changed
One round trip for the membership sync
One round trip for collection state
One round trip for CGKA sync
Two round trips for sedimentree sync
We should be able to simplify this. One the initial message when we begin membership sync we can send the clients first 5 (say) membership RIBLT symbols and first 5 collection state symbols. In the common case the server will be able to decode these symbols (because only one document has changed) and immediately determine which document has changed, then the server can send back a response with the sedimentree summary for the changed document and the first 5 symbols of the server CGKA RIBLT state. The client will in most cases be able to determine if any CGKA ops are missing and immediately download any missing document state.
Thus in the common case we can sync graph updates (auth, content, etc) in just two round trips.
The Ink & Switch Dispatch
Keep up-to-date with the lab's latest findings, appearances, and happenings by subscribing to our newsletter. For a sneak peek, browse the archive.